

Scikit-learnを使って基本的な予測問題の流れをつかみたい
Pythonが流行っている昨今、Scikit-learnやDeepLearningライブラリを使ってみたいと思っている方、多いのではないでしょうか。
こんにちは、ライターのフクロウです。Pythonのインストラクターをしています。
この記事では、機械学習ライブラリ「Scikit-learn」(skleran)を使って、データの予測問題にチャレンジする流れを紹介します。解析に使うライブラリはsklearnだけなので(Deep Learningは触りません)、手軽に始められると思いますよ!
この記事はこんな人のために書きました。
- Pythonで機械学習に挑戦したい
- データを集めるところから最後までの流れが知りたい
本記事を読む前に、Pythonがどんなプログラミング言語なのかをおさらいしておきたい人は次の記事を参考にしてください。
→ Pythonとは?特徴やできること、活用例をわかりやすく簡単に解説
なお、その他のPythonの記事についてはこちらにまとめています。
Pythonで機械学習に挑戦しようとする皆さん、Scikit-learnを使って基本的な予測問題の流れを学ぶことは素晴らしい第一歩です。しかし、独学での学習に不安を感じることもあるでしょう。そんな時には、専門的なサポートを受けられる環境を活用してみるのも一つの手です。
今こそAIの力を最大限に活用し、時間や収入、キャリアの可能性を広げる時です。実践スキルを身につけ、具体的なノウハウを得ることで、AIとWebスキルを活用した収益化の道が開けます。興味を持たれた方は、ぜひセミナーの詳細を確認してみませんか?
実験目的
Boston house-prices (ボストン市の住宅価格)データを使い、Scikit-learnのランダムフォレスト回帰で住宅価格を予測してみましょう。
実験の前準備
ライブラリのimport
まずは必要なライブラリをインポートしましょう。
# 計算で使うかもしれないNumPy import numpy as np # データフレームを使うためにPandas import pandas as pd # 可視化ライブラリ import matplotlib.pyplot as plt import seaborn as sns sns.set() # もしもJupyter notebookで使う場合は、以下のコマンドが必要 %matplotlib inline
次にscikit-learn関係をインポートします。
# データセット from sklearn import datasets # ランダムフォレスト回帰のクラスをRFRというあだ名を付けてimport from sklearn.ensemble import RandomForestRegressor as RFR # 教師データとテストデータに分割してくれる from sklearn.model_selection import train_test_split # 平均二乗誤差を計算する関数 from sklearn.metrics import mean_squared_error # もしパラメータ探索がしたい場合は以下もimport from sklearn.model_selection import GridSearchCV # もしデータの標準化がしたい場合は以下もimport from sklearn.preprocessing import StandardScaler
データの読み込み
回帰問題のベンチマークによく使われるボストンデータセットを読み込みます。ボストンデータの詳しい情報はscikit-learnに付属しているデータセットを読むのがおすすめです。
ここではデータを読み込んでから、train_test_splitで教師データとテストデータに分割してみます。
# ボストンデータの読み込み boston = datasets.load_boston() # 教師データとテストデータに分割 train_data, test_data, train_target, test_target \ = train_test_split(boston.data, boston.target, test_size=0.2)
読み込んだデータセットをデータフレームにして表示してみましょう。すべてを表示すると膨大です。ここでは先頭の10行だけ表示します。
# データフレーム化 train_df = pd.DataFrame(train_data, columns=boston.feature_names) # 上から10行を表示 train_df.head(10)
# 予測したい値 train_df["MEDV"] = train_target train_df.head()
データのチェック
まずはデータの個数と、どんなデータ型をもっているのかを確認しましょう。
train_df.info()
[出力結果]
<class 'pandas.core.frame.DataFrame'> RangeIndex: 404 entries, 0 to 403 Data columns (total 14 columns): CRIM 404 non-null float64 ZN 404 non-null float64 INDUS 404 non-null float64 CHAS 404 non-null float64 NOX 404 non-null float64 RM 404 non-null float64 AGE 404 non-null float64 DIS 404 non-null float64 RAD 404 non-null float64 TAX 404 non-null float64 PTRATIO 404 non-null float64 B 404 non-null float64 LSTAT 404 non-null float64 MEDV 404 non-null float64 dtypes: float64(14) memory usage: 44.3 KB
さて、読み込んだデータに欠損値があったら計算がおかしくなります。なのでisnullメソッドで欠損値の数を数えてみましょう。
もしも欠損値があったら、これを別の数字で置換する必要があります。
# null(None)があれば1以上の値になります。 train_df.isnull().sum()
[出力結果]
CRIM 0 ZN 0 INDUS 0 CHAS 0 NOX 0 RM 0 AGE 0 DIS 0 RAD 0 TAX 0 PTRATIO 0 B 0 LSTAT 0 MEDV 0 dtype: int64
ここでは欠損は無いことがわかったので、次に進みます。
統計量を表示してみましょう。実はDataFrameにはdescribeという便利なメソッドがあるので、コレを使うことでDataFrameの統計量を一気に表示できます。
# 統計量の表示 train_df.describe()

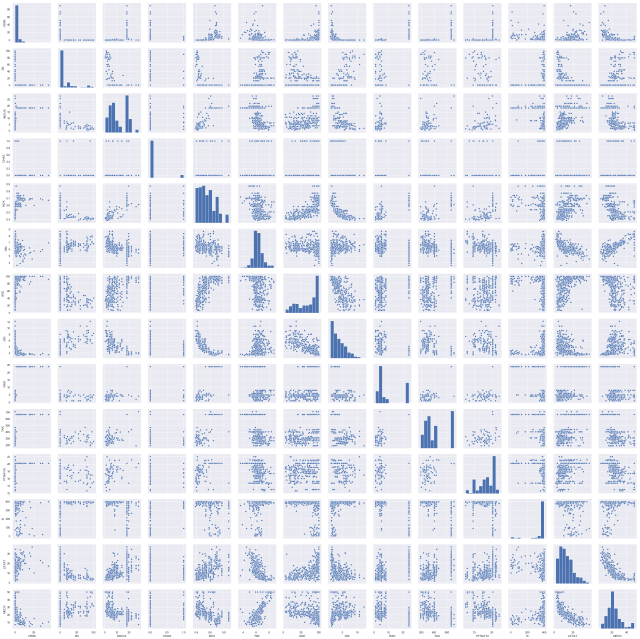
特徴同士の関係を確認してみましょう。ここではseabornのpariplot関数で一気にやってしまいます。
このグラフを見ることで、どの特徴がどの特徴に似ているのかがわかります。非常に似ている特徴があるならば、それを参考に特徴を省くことも出来ます。
ここではデータの特性についての考察は行っていません。本来であれば特徴エンジニアリングを行います。
予測精度が高くなるような特徴を作ったり、不要な特徴を削除したりと言った作業がこれに該当します。
回帰分析
ランダムフォレストの学習
今回は住宅価格をそれ以外の情報から予測するのが目的です。ランダムフォレスト回帰を使ってやってみましょう。
sklearnには様々な機械学習モデルが実装されていますが、データと目的にあったものを選ぶ必要があります。これについては勉強する以外にありませんが、一つの指針としてsklearnのチートシートを見てみるのも手です。

RFRクラスは並列処理で訓練時間を短縮できるので、n_jobsに使えるコア数を指定しておきましょう。
rg = RFR(n_jobs=-1, random_state=2525) # n_jobs=-1でコアすべてを使って並列に学習できる rg.fit(train_data, train_target) # 訓練
[出力結果]
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=-1,
oob_score=False, random_state=2525, verbose=0, warm_start=False)
このような問題では、このようにデフォルトの引数をそのまま使うのは賢いやり方ではありません。
ちゃんとやる場合はグリッドサーチやランダムサーチなどのパラメータサーチを行って、もっともらしい値を探す必要があります。また、クロスバリデーションによってモデルの評価を行う必要もあります。
学習結果の確認
まずは訓練データにどのくらいfitできたか確認してみましょう。
ここでは訓練データの住宅価格(target)と、モデルの予測した住宅価格の平均二乗誤差を出してみましょう。(この値は小さいほど嬉しいものです。)
predicted_train_target = rg.predict(train_data) mean_squared_error(train_target, predicted_train_target)
[出力結果]
0.9729691006642613
それなりによく出来ていることがわかります。ですがこれで安心してはいけません。訓練データに対してfit出来ていても、テストデータに対してどうなのかはまだわかりませんからね。
ではテストデータの方も表示してみましょうね。
predicted_test_target = rg.predict(test_data) mean_squared_error(test_target, predicted_test_target)
[出力結果]
10.828846078431374
R^2のスコアも見てみます。
rg.score(test_data, test_target)
[出力結果]
0.8540704890041346
この値はそこまで良いものではありませんね。また、これを更に良くするには、先程紹介したパラメータサーチやクロスバリデーションを使ってチューニングを行ったり、データの前処理をよりしっかり行う必要があります。
また、ここではランダムフォレストだけを使いましたが、SVMなどの別の機械学習モデルを複数使い、それらをアンサンブルすることでも、さらなる性能向上が期待できます。
まとめ
この記事では、Pythonを使ってシンプルなデータの予測を行いました。
scikit-learnは非常に便利で使いやすいライブラリです。例えば、今回使ったランダムフォレストについても、どういう手法なのか分からなくてもある程度動かすことが出来ました。ただし、しっかりと使いこなすには勉強が必要です。自分で実装できるようにとまでは行かないでも、どういう手法なのかイメージが湧く程度までは最低限覚えておきたいですね。
最後に、ここで紹介した処理の一覧はあくまでも流れを把握するのが目的だと思ってください。記事中に散りばめた「これをしたほうがいい」という前置きのあるキーワードを自分で調べて試してみるのが重要ですよ。




