

Chainerを使うとニューラルネット・深層学習(Deep learning)を、シンプルで読みやすい形で実装できますね。
ニューラルネットのモデルの実装をシンプルにしたら、次はモデルをトレーニングするコードをシンプルにしましょう!
Chainerではニューラルネットのトレーニングを簡単に実装するための機能として、Trainerというクラスを提供しています。
このTrainerを使いこなすことで、高機能でバグの少ないプログラムを作る事ができます!
この記事では、
- Trainerとは
- Updaterとは(Trainerを使うために必要)
などの基本的な事から
- Extensionを使ってTrainerをカスタマイズ!
などの発展的な内容について解説していきます!
ChainerのTrainerクラスを使いこなすことで、ニューラルネットのトレーニングがよりシンプルかつ効果的になりますね。しかし、AI技術の進化は日々加速しており、最新の生成AIを活用するスキルが求められる時代です。「自分のスキルが追いついていないかも…」と感じる方には、専門的なサポートを受けることが解決策となるかもしれません。
このような環境で学べば、生成AIを活用したWeb制作の実践スキルを身につけることができます。具体的なノウハウを凝縮してお伝えする場があり、実際にAIツールを操作しながら体験することで、即戦力となるスキルを手に入れることが可能です。
少しでも興味を持たれた方は、セミナーの詳細を確認して、自分に合った学びの機会を探してみませんか?
Trainerとは
ニューラルネットのパラメータトレーニングのコードには様々な書き方があります。
それでも多くの場合、必要な処理は7つです。
- 教師データのループ処理
- ミニバッチの前処理
- ニューラルネットのフォワードプロパゲーション
- ニューラルネットのバックプロパゲーション
- パラメータの更新
- バリデーションデータを使ったその時点での評価
- その時点での結果の保存と表示
だいたいやりたいことは決まっているんです。
これらのコードを素直に書くと、学習ループの中は結構ごちゃごちゃしてきます。
深層学習のモデルの実装/パラメータのチューニング(Optimizerを何にするか、学習率をどうするか、minibatchの大きさをどうするか、パラメータの初期値をどうするか、 etc…)などの本質的な部分に力を入れたいのに、それ以外の部分で時間を取られるのは避けたいですよね。
そんなとき、Trainerが力になってくれます。
Trainerはニューラルネットの学習ループをシンプルにまとめてくれる様々な機能を提供してくれます。
実際に簡単な実験を行うコードを例に、その使い方と便利さに触れていきましょう!
トレーニングをシンプルに!Trainerを使ってみよう!
では実際に、Trainerを使ったニューラルネットの学習を見ていきます。
Chainerのプログラムを書くために、まずは必要な機能をimportしましょう!
import numpy as np import chainer from chainer.backends import cuda from chainer import Function, gradient_check, report, training, utils, Variable from chainer import datasets, iterators, optimizers, serializers from chainer import Link, Chain, ChainList import chainer.functions as F import chainer.links as L from chainer.training import extensions
ChainerでDeep learningをするにあたり、上のようなimportをして置くと便利です。
これで大体の場合に対応できます。
データを用意しよう
ここでは例として、手書き文字認識をやってみましょう。
今回は最も簡単な手書き文字認識のデータセットとして、MNISTというデータセットを使います。
MNISTは0から9までの数字を手書きしたグレースケールの画像が集められています。
28×28ピクセルの画像から、その画像がどの数字を書いたものなのかを当てる問題によく使われます。
データの内訳:
| 教師データ | 55000個 |
| バリデーションデータ | 5000個 |
| テストデータ | 10000個 |
Chainerでは、MNISTを読み込む(手元に無ければダウンロードしてくれる)関数があります。
まずはこれを使ってデータを手に入れましょう。
from chainer.datasets import mnist train, test = mnist.get_mnist()
このコードを実行すると、最初の一回目ならデータがインターネットを介してダウンロードされます。
少し時間がかかるかもしれませんから、注意してくださいね。
この方法でデータを読み込むと、教師データが60000個、テストデータが10000個となります。(※バリデーションデータが教師データの中に含まれている)
それぞれのデータには、28×28=784個の数字が含まれています。
試しに28×28の行列に戻して、データの中身を見てみましょう。
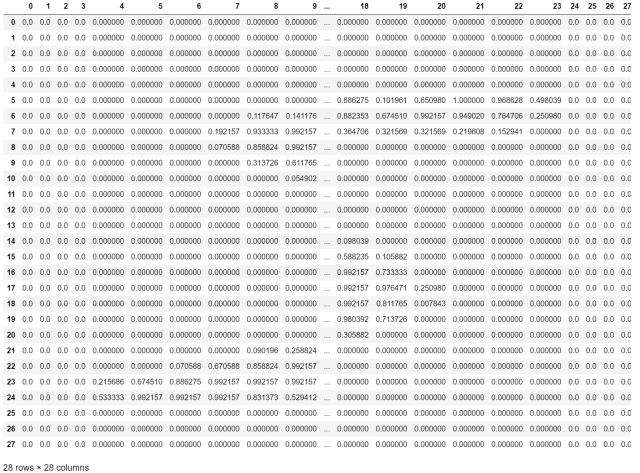
これが一枚の画像を表したデータです。
0~1の数字でできています。1に近いほど黒い事を表していて、0に近いほど白いことを表します。
この行列は以下のような画像が元になっています。
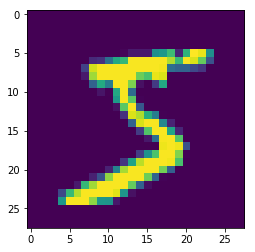
これをCNN(畳み込みニューラルネットワーク)やMLP(多層ニューラルネットワーク)に入力して、10通りのクラス分類を行います。
それでは、ニューラルネットで学習するために、データをミニバッチに分けましょう。
これも、Chainerに用意されている機能を使うことで簡単に行うことが可能です!
minibatch_size = 128 train_iter = iterators.SerialIterator(train, minibatch_size) test_iter = iterators.SerialIterator(test, minibatch_size, False, False)
iterators.SerialIteratorを使いことでデータをminibatchサイズごとに取り出す事ができます。
第一引数にデータを、第二引数にミニバッチサイズを指定します。
ここではミニバッチのサイズを128にしてみましたが、色々と変えていい値を見つけてみてください。
これでデータの準備は完了です。
トレーニングするmodelを用意しよう
次はニューラルネットを実装します。
ここでは四層のMLPを使います。
class MLP(Chain):
def __init__(self, n_mid_units=100, n_out=10):
super(MLP, self).__init__()
with self.init_scope():
self.l1 = L.Linear(None, n_mid_units)
self.l2 = L.Linear(None, n_mid_units)
self.l3 = L.Linear(None, n_out)
def __call__(self, x):
h1 = F.relu(self.l1(x))
h2 = F.relu(self.l2(h1))
return self.l3(h2)
これでMLPの実装ができました。
Chainerによるモデルの実装方法については以下の記事を参考にしてください。

このクラスから実際に使うMLPのインスタンス(実体)を作るには、以下のようにします。
model = MLP()
# Classifierでmodelをラップすることで、modelに損失の計算プロセスを追加します。
# 引数に損失関数を指定しない場合は、softmax_cross_entropyを使います。
model = L.Classifier(model)
# GPUが使える場合は、gpu_idに0を代入します。ない場合は-1とします。
gpu_id = 0
if gpu_id >= 0:
model.to_gpu(gpu_id)
先程作ったMLPクラスからmodelという実体を作ります。
L.ClassifierはmodelのChainを継承したクラスのインスタンスを受け取ると、それに損失関数を追加してくれます。
何も指定しなければ、損失関数としてsoftmaxクロスエントロピーを追加してくれるので、今回はそのまま使いましょう。
また、もしもGPUを使うならgpu_idを0、CPUを使うなら-1にしてください。
to_gpuでMLPをGPUに対応させる事ができます。
Optimizerを用意しよう
ニューラルネットのパラメータの更新量を決めてくれるのがOptimizer(オプティマイザー)です。
代表的なOptimizerは以下の6つ。
- SGD
- MomentumSGD
- RMSprop
- AdaGrad
- AdaDelta
- Adam
これらのOptimizerの詳しい解説を書いてくださっている記事があります。
より詳しく理解したい時に読んでみてください。
これ以外にもたくさんのOptimizerが開発されていますが、大体の場合はこれらの中から良さそうなものを選ぶ事になります。
特にSGDとAdamがよく使われるのでは無いでしょうか。
ここではAdamを使うことにします。Adamは学習率の調整を自動でやってくれるような機能があるので、困ったときはこれを使うと良いでしょう。
Optimizerは以下の様にして用意します。
# オプティマイザを選択 optimizer = optimizers.MomentumSGD() # オプティマイザにmodelをセット optimizer.setup(model)
optimizersには先程紹介したようにいくつかの種類があります。
どのオプティマイザーを選ぶかも、ニューラルネットの学習をうまく行うための重要な要素です。
これも色々と取り替えて試してみてください。
Optimizerには最適化したいパラメータを持ったChainを渡します。
optimizer.setup(ニューラルネットのインスタンス)の形で指定することで設定できますので、忘れないようにしましょう。
Updaterを用意しよう
Optimizerを使って、実際にパラメータを更新するのがUpdater(アップデーター)です。
Updaterは以下の様にして用意します。
# IteratorとOptimizerを使うupdaterを作る updater = training.updaters.StandardUpdater(train_iter, optimizer, device=gpu_id)
Updaterの最もシンプルな実装はStandardUpdaterです。
学習データとoptimizer、必要なら使うデバイスのidを渡しましょう。
Trainerを用意しよう
学習ループ自体を制御してくれるのがTrainer(トレーナー)です。
ここまででTrainerを使う準備ができたので、後はこれらをTrainerにセットしましょう。
Trainerは以下のようにして用意します。
# 学習する回数を決める。 max_epoch = 10 # Trainerを用意する。updaterを渡すことで使える。epochを指定する。outはデータを保存する場所。 trainer = training.Trainer(updater, (max_epoch, 'epoch'), out='mnist_result')
これで大体の準備が完了しました。
outという引数がありますが、これはデータを保存する場所(ディレクトリのパス)を指定しています。
ここでは仮にmnist_resultというディレクトリを指定していますが、別の名前でもOKです。使いやすいものにしましょう。
Trainerを使ってニューラルネットをトレーニングしよう
最もシンプルなTrainerはこれで完成です。
後はtrainerのrunメソッドをキックするだけで学習がスタートします。
trainer.run()
ですがこれだけだと、学習のモニタリングや記録ができません。
これらを行うにはTrainerに色々なExtensionを追加する必要があります。
次の章で紹介するので、これらも一緒に習得しておきましょう!
Trainerに便利機能を追加!Extensionを活用しよう!
Extensionとは
Extensionとは、Trainerに様々な便利な機能を追加する仕組みです。
学習の記録、モデルの保存、学習中のログ出力など様々な機能が追加できます。
たくさんのExtensionが既に提供されているので、好きなものを選んで自分のTrainerをカスタマイズしましょう!
Extensionの代表的な機能については、以下のブログがわかりやすい解説をしてくださっています。

ExtensionでTrainerをもっと便利に!
先程作ったTrainerをExtensionでカスタマイズしてみましょう!
学習のモニタリング、損失関数と評価関数のグラフの作成、ログの保存、モデルの保存を追加します。
from chainer.training import extensions
# Trainerに便利機能を追加する。
# ログファイルを保存する機能を追加
# トレーニング情報を定期的に端末に表示する機能
trainer.extend(extensions.LogReport())
# 定期的に状態をシリアライズ(保存)する機能
trainer.extend(extensions.snapshot(filename='snapshot_epoch-{.updater.epoch}'))
trainer.extend(extensions.snapshot_object(model.predictor, filename='model_epoch-{.updater.epoch}'))
# テストデータを使ってモデルの評価を行う機能
trainer.extend(extensions.Evaluator(test_iter, model, device=gpu_id))
trainer.extend(extensions.PrintReport(['epoch', 'main/loss', 'main/accuracy', 'validation/main/loss', 'validation/main/accuracy', 'elapsed_time']))
# 損失関数の値をグラフにする機能
trainer.extend(extensions.PlotReport(['main/loss', 'validation/main/loss'], x_key='epoch', file_name='loss.png'))
# 正答率をグラフにする機能
trainer.extend(extensions.PlotReport(['main/accuracy', 'validation/main/accuracy'], x_key='epoch', file_name='accuracy.png'))
trainer.extend(extensions.dump_graph('main/loss'))
これでカスタマイズは完了です。
では、このTrainerを走らせてみます。
trainer.run()
このTrainerはExtensionにより、以下のようなログを表示してくれます。
epoch main/loss main/accuracy validation/main/loss validation/main/accuracy elapsed_time 1 0.553869 0.842684 0.27381 0.920589 3.79628 2 0.241893 0.930387 0.188985 0.943434 7.58965 3 0.181355 0.947095 0.157821 0.952136 11.3265 4 0.144791 0.958033 0.132128 0.95985 15.1851 5 0.11942 0.964869 0.114496 0.964399 18.9233 6 0.101038 0.970449 0.107447 0.966871 22.6915 7 0.0879229 0.974014 0.0944294 0.970926 26.4991 8 0.0760927 0.977214 0.0894594 0.972211 30.2399 9 0.0685829 0.979977 0.0908658 0.973398 34.002 10 0.0608839 0.982276 0.0808326 0.974189 37.769
これで学習中にどのような動作をしているのか、モニタリングが簡単にできて便利ですね。
また、損失関数と正答率もグラフにしていました。
これも見てみましょう。
まずは損失関数です。
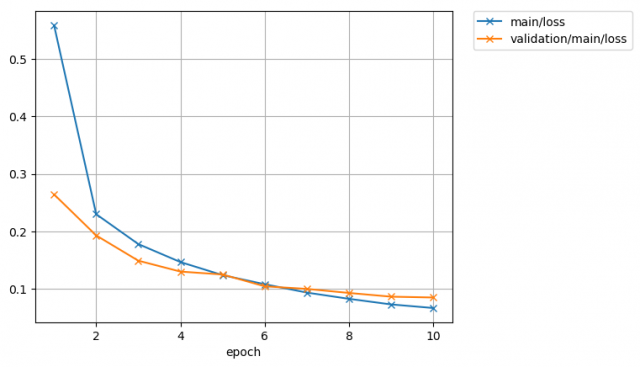
このグラフから損失関数が小さくなるようにニューラルネットを学習できている事がわかりますね。
テストデータをバリデーションデータとして使っていますが、本来は教師データの中から一部を切り取ってバリデーションデータとして使うと良いでしょう。
テストデータは学習のモニタリングには使わないように!
次に正答率です。
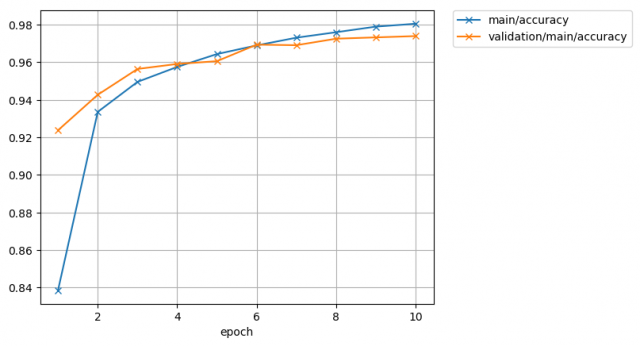
ここでも大方、教師データの正答率は綺麗に上がっていっている事がわかります。
また、バリデーションデータの正答率については、少しグラグラとしていますが、徐々に正答率が上がっている事がわかります。
過学習という、教師データに対して適応しすぎる状態になった場合は、バリデーションデータの損失関数や正答率が下がってしまいます。
そんなときはハイパーパラメータ(学習率やミニバッチサイズなど)を変更してみるといいでしょう。
まとめ
この記事ではTrainerと、Trainerに関係するChainerの便利な機能を紹介しました。
- Optimizer
- Updater
- Trainer
- Extension
これらの機能を使いこなすことで、深層学習のプログラミングをより簡単に、高速に行う事ができます!
この記事のサンプルコードを手元で試しながら解説を読んで、Trainerをマスターしてくださいね!




