

Deep learningのモデル・実行コードを直感的に記述できるPythonのフレームワーク、Chainerの使い方を学んでいきましょう。Chainerの使い方を学ぶことで、ニューラルネットやDeep learningについても理解が深まると思います。この記事では、
Chainerを使ったニューラルネットの定義の仕方やニューラルネットの実行コード(学習用コード)の書き方という基本的な内容から、
- Link・Function・Chain・Variableの4つの機能の紹介
- ChainerをGPU上で使う方法
などの発展的な内容についても解説していきます。これらを学ぶことで、基本的なChainerの使い方がわかるようになります!この記事を読んで、一緒にChainerの勉強を始めましょう!
なお、Pythonの記事については、こちらにまとめています。
Chainerの使い方をマスターすることで、AI技術の基礎をしっかりと築くことができます。しかし、AI技術を実際に活用して収益を上げるためには、より実践的なスキルが求められます。もし「このままでは不安だ」と感じているなら、実践的なスキルを身につけるための環境を探してみるのも一つの手です。
AI技術を活用したWeb制作のスキルを学べる場では、すぐに使える具体的なノウハウを凝縮してお伝えします。生成AIの圧倒的なベネフィットを理解し、収益化の流れを学ぶことで、将来の収入に対する不安を解消しませんか?セミナーの詳細をみることで、自分に合った学びのスタートを切りましょう。
ディープラーニング/ニューラルネットとは
まずはDeep learningとは何なのか、について整理していきましょう。動物の脳のニューロンの様に、汎用的な機能をもった機械があれば便利ですよね。ニューラルネットワークは脳のニューロンのネットワークの仕組みをコンピューターの上で再現したモデルです。
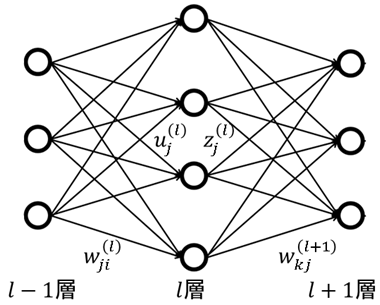
上の図は、三層の単純なニューラルネットワークのイメージ図です。コンピューター上で再現されるニューラルネットワークは、データを入力層(l-1層)で受け取り、隠れ層(l層)を通り、出力層(l+1層)から答えを返す様に作られています。このモデルを使って、目的のタスクの答えを出してくれる関数を近似します。
ですが残念ながら、人間の脳のような振る舞いが完全にできるわけではありません。また、スタート地点がどうあれ、現在の最新のニューラルネット・ディープラーニングの研究では脳を再現する事にこだわらず、様々な研究分野の技術が応用されています。
ディープラーニングと呼ばれるモデルは、そんなニューラルネットワークのネットワークをより深く(長く)して、性能を向上させたものの総称なんです。
ニューラルネット(ディープラーニング)では、正しい答えとニューラルネットの予測した答えとの誤差などを損失関数と呼びます。この損失関数の値が小さくなるように、パラメータの値を変えていく事ことで、ニューラルネットを学習(パラメータの最適化)させる事ができます。
Chainerとは
次はPythonでDeep learning/Neural Netsのプログラムを書くためのフレームワーク、Chainerについて整理しましょう。
Chainerについては冒頭でも触れましたね。国産のDeep learningフレームワークで、とても直感的にDeep learningのコードを書く事ができることから、たくさんの人が利用しています。
この直感的に書ける、というのはPythonのコードをそのまま書くだけでDeep learningのモデルが作成でき、その上GPUを使った高速化までできてしまうということです。
Pythonの上にミニ言語を実装して、その中でコードを書くタイプのフレームワークもあります。Chainerではそれらに比べ、学習コストの小ささ、デバッグのしやすさ、などの点において優れていると思います。
わからないことがあった時に、インターネットで調べれば日本語の情報がたくさん見つかりますし、バグの修正や最新技術への対応も頻繁に行われているんです。そういう点においても、Chainerはオススメです。侍エンジニアブログでも、Chainerについて注目して解説記事を出しています。

リンクをチェックして、Chainerをインストールしてみてください。次の章からは実際にプログラムを動かしてみます。是非試してみてください。
Chainerの機能
それではChainerの機能を見ていきましょう。ここではChainerが提供している便利な機能の、代表的なものをまとめて紹介します。
LinkとFunction
ニューラルネットではWeight(結合重み)とBiasという2つのパラメータを使って、目的の値を出力する関数に近いものを作ります。パラメータを目的関数を目印に更新していくことが、ニューラルネットの学習です。
ニューラルネットの図を見てみると、ある層のニューロンと、その層に隣り合った層のニューロンが繋がっている事がわかります。このニューロン同士のつながりは、それぞれつながりの強さが違います。このつながりの強さの事がWeightです。
そして、図では省略されていますが、ある層のニューロンの出力とWeightとを掛け合わせた値にただ足してあげるパラメータとして、Biasがあります。
これらのパラメータを持ったニューラルネットの関数を、ChainerではLinkと呼びます。Linkはimportの際にLという名前にしてあげましょう。Chainerを使うときの約束です。
import chainer.links as L
また、入力された信号を受けて、ニューロンが発火するかどうかを真似た関数として、活性化関数というものを使います。活性化関数にはパラメータが無いので、これらはLinkでは無いですね。
このような関数をChainerではFunctionとしてまとめています。これも約束でimportの際にFという名前にしてあげましょう。
import chainer.functions as F
これらはプログラムの最初でimportしてあげると綺麗です。
Chainとは
LinkやFunctionをまとめて管理するのがChainです。Chainはニューラルネットを実装するクラスの親クラスとして提供されているので、自分でニューラルネットを実装する時に必ず使います。これを継承することでニューラルネットを実装する時にあると便利な機能のあれこれが簡単に使えるようになります!
継承は以下のように、クラスの横にカッコで親クラスを書いてあげればOKです。
class MyNeuralNet(chainer.Chain):
次の章で実際にニューラルネットを実装しますので、Chainの詳しい使い方はそこで確認しましょう!
Variableとは
ニューラルネットの学習の際に、パラメータを更新する値を決める必要があります。Chainerでは、ニューラルネットにデータが入れられてから出力を返すまでの計算の流れ(=フォワードプロパゲーション)を計算グラフとして記録し、これを逆に辿ることで自動的に行なってくれます。
自分でニューラルネットの学習アルゴリズムである、バックプロパゲーション(誤差逆伝播法)を実装する必要が無いのは嬉しいですね。これを実現するために、Variableという機能を使います。
ニューラルネットの学習時に使う教師データなどの値は、全てVariableというクラスにする必要があります。忘れないようにしましょう。
ニューラルネットの実行コードを書いてみよう!
では実際に、簡単な実験を通して、三層のニューラルネットのChainer実装を見ていきましょう。ここではアヤメの花の分類問題をニューラルネットで解きます。以下のようにライブラリをimportしましょう。
# まずはchainerのimport from chainer import Chain, optimizers, Variable import chainer.functions as F import chainer.links as L # 次はnumpyのimport import numpy as np # sklearnのimport from sklearn import datasets, model_selection # 可視化ライブラリのimport import seaborn as sns import matplotlib.pyplot as plt
上3つはChainer関連のimportです。これ以外にもたくさんの機能がありますが、ここでは簡単のためにこれらだけをimportしておきます。
まずはデータを知ろう
ニューラルネットに限らず、機械学習を使ったデータ解析やアプリケーションの開発では、まず最初に対象のデータの特性を知る事が重要です。アヤメの花のデータセット(iris dataset)には、3つのクラスがあり、それぞれ50個ずつデータがあります。それぞれのデータは4つの特徴を持っています。
- がく片の長さ
- がく片の幅
- 花弁の長さ
- 花弁の花
の4つです。これから挑戦するのは与えられたデータがどのクラスのものなのかを当てる問題になります。データの全体像を知るために、簡単な可視化を行います。Jupyter notebookやIPythonの上で、以下のコードを実行してみてください。
iris_df = sns.load_dataset("iris")
sns.pairplot(iris_df, hue="species")
すると以下のようなグラフが表示されると思います。
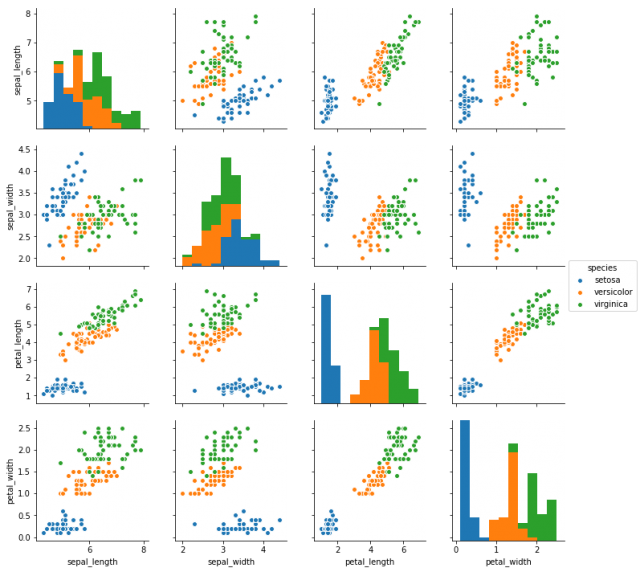
これでiris datasetのデータの特性がわかりやすくなりましたね。グラフから分かる内容を簡単にさらってみましょう。青、オレンジ、緑のそれぞれの点は3つのクラスのデータを表しています。
このグラフによると、比較的青のデータは他の2クラスと綺麗に別れている事がわかります。逆に、緑とオレンジのデータはどの特徴の組み合わせでも少し被っているところがあるようです。このグラフにより、少し緑とオレンジの識別は難しいかな?という目測が立てられます。
三層のニューラルネットの実装
それではirisデータのクラス分類を行うために、3クラスの識別を行うニューラルネットを実装します。分類したいデータがどのクラスに割り当てられるのかを、最期の層の出力で確率として出せればわかりやすいですね。実装コードは以下のようになります。
class MLP(Chain):
""" 三層のニューラルネットワーク(MLP)
"""
def __init__(self, n_hid=100, n_out=10):
# Chainer.Chainクラスを継承して、Chainクラスの機能を使うためにsuper関数を使う
super().__init__()
# 結合重み(weight)やバイアス(bias)などのパラメータを持つ関数を定義
with self.init_scope():
self.l1 = L.Linear(None, n_hid)
self.l2 = L.Linear(n_hid, n_out)
def __call__(self, x):
hid = F.relu(self.l1(x))
return self.l2(hid)
これだけなんです。短くて読みやすいと思いませんか?上から一緒に読み解いていきましょう。まずは1行目、ここでMLPクラスを宣言します。親クラスにChainを指定する事を忘れないように。次に__init__の中で、super関数を使い親クラスの__init__を呼び出します。
__init__は初期化を行ってくれるメソッドでしたね。with self.init_scope():のブロックではLinkを定義します。そしてフォワードプロパゲーションを実装する__call__です。__call__に書いたコードは、インスタンスを関数として使うと呼び出されます。
中で行っている処理は以下のとおりです。
- __call__の引数xに入力データを渡します
- xを全結合層self.l1に通してWx+bを計算。
- ランプ関数F.reluを使い、非線形の変換を行う。
- 隠れ層の出力hidを全結合相self.l2に通してWx+bを計算。
ここで、中間層で使ったランプ関数(relu)とは、以下のような動きをする関数です。
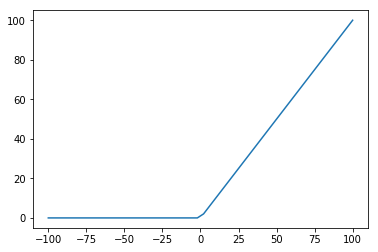
入力が0以下なら0に置き換えた値を返してくれる非線形関数です。これが隠れ層の活性化関数として使われます。また、本来ならば出力層の活性化関数としてsoftmax関数を使います。
ですがChainerではsoftmax関数に入れる前の値を受け取る損失関数が用意されていますので、ここでは省略しています。注意してください。
実行コードを書いてみよう
Chainerでニューラルネットのモデルを実装すると、それだけでほとんど実行は完了です。自動微分の実装されたChainerでは、ニューラルネットのフォワードプロパゲーションを実装しておけば、バックプロパゲーションの実装はいらないと先ほど紹介しましたね。
それでは実際のデータを使ってニューラルネットをトレーニング(学習)してみましょう。コード中にコメントを書き込みました。一行ずつ読んでみてください。まずは学習ステップの前までです。
# sklearnでirisデータを読み込み iris = datasets.load_iris() # データを教師データ、テストデータ、教師データの正解クラス、テストデータの正解クラスに分割 train_data, test_data, train_label, test_label = model_selection.train_test_split(iris.data.astype(np.float32), iris.target) # 先程作ったニューラルネットのユニット数を指定して、インスタンスを作ります。 model = MLP(20, 3) # ニューラルネットの学習方法を指定します。SGDは最も単純なものです。 optimizer = optimizers.SGD() # 学習させたいパラメータを持ったChainをオプティマイザーにセットします。 optimizer.setup(model) # dataをVariableに変換します。 train_data_variable = Variable(train_data.astype(np.float32)) train_label_variable = Variable(train_label.astype(np.int32))
次に、学習ステップです。
# 学習の様子を記録するために、リストを作っておきます。
loss_log = []
# 学習ステップです。ここでは200回行います。
for epoch in range(200):
# パラメータの勾配を初期化
model.cleargrads()
# フォワードプロパゲーション
prod_label = model(train_data_variable)
# 損失関数を計算
loss = F.softmax_cross_entropy(prod_label, train_label_variable)
# 損失関数の値を元に、パラメータの更新量を計算
loss.backward()
# パラメータを更新
optimizer.update()
# 損失関数の値を保存しておきましょう。後で確認できます。
loss_log.append(loss.data)
学習時の損失関数の動きを見てみましょう。この値が小さくなるようにパラメータを学習させました。
plt.plot(loss_log)
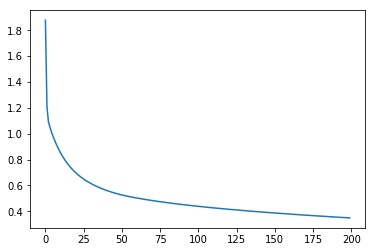
綺麗に値が減少していますね!学習はうまくいったようです。では次に、テストデータを使って認識率を確認します。
# テストデータをVaribleにしましょう test_data_variable = Variable(test_data.astype(np.float32)) # フォワードプロパゲーション y = model(test_data_variable) # Softmax関数でクラス確率を出します y = F.softmax(y) # 3クラス中で一番確率の大きいものをデータが割り当てられたクラスとします pred_label = np.argmax(y.data, 1) # 正答率を計算 acc = np.sum(pred_label == test_label) / np.sum(test_label) print(acc)
[出力結果]
0.9459459459459459
これで、ここで作ったニューラルネットはirisデータを約94%正しく分類できた事がわかりました。お疲れ様です。これであなたはChainerとニューラルネットをマスターする第一歩を踏み出しました!
GPUで実行するには
Deep learningやビッグデータなどに対応するためには、計算の高速化が必要です。そこで注目されているのがGPUです。CPUの何杯も高速な計算ができるGPUは、Deep learningには必須のパーツです。
もちろんChainerでも、GPUに対応したプログラムが書けます。具体的には、Chainerが裏で使っている数値計算ライブラリをNumpyからCupyに変えるだけです。
CupyはCUDA(NVIDIAのGPUを使うためのプログラミング言語)で書かれた計算を、Numpyとほとんど同じように使う事ができるすごいライブラリです。
さて、先程作ったモデルをGPUに対応させてみましょう。
# モデルをGPUに対応 model.to_gpu() # VariableをGPUに対応 train_data_variable.to_gpu() train_label_variable.to_gpu()
ChainerのオブジェクトのGPU対応には、to_gpuメソッドを使います。後はCPUを使ったときと同様に学習させてください。CPU版では裏でNumpyを使っていましたが、GPU版ではCupyを使って計算を行ってくれます!
学習用コードが簡単に書けるTrainerとは?
ニューラルネットの学習コードを、より簡単に書けるTrainerという機能がChainerでは提供されています。これを使うことで、この記事のサンプルコードにあった学習ステップに関する部分をより短くする事ができます。
また、Trainerを使うことで学習の様子のモニタリングも簡単にでるので、Chainerに慣れてきたら是非使うことをオススメします。Trainerについては、別の記事で詳しく説明します。
まとめ
どうでしたか?駆け足になりましたが、この記事ではChainerの基本的な使い方を紹介しました。Chainerは初心者でも簡単にニューラルネットに触れる事ができる素晴らしいライブラリです。
「流行りのDeep learningに入門したい!」という方は、是非ともChainerにチャレンジして、最新技術を手軽に楽しんでみてはいかがでしょうか。
なお、今Pythonを学習している方は以下の記事もどうぞ。
はじめてPythonを使う方でもわかりやすいように、Pythonでできることやその学習法などを中心にまとめています。
復習にも使えると思いますので、ぜひ一度ご覧になってみてくださいね。
【Python 入門完全攻略ガイド】





