

正規表現で文字列を抽出する方法が知りたい
正規表現を使って文字列を置換する方法が知りたい
指定したパターンに一致する文字列を抽出したい場合、正規表現がよく使われます。しかし、正規表現はそもそもわかりにくかったり、使い方がなかなか身につかないなどの問題があります。そこでこの記事では、正規表現の基礎から使いこなすために、
- 【基礎】正規表現について
- 【基礎】正規表現を使うためのモジュールと4つの関数、メソッド
- 【発展】正規表現を使ってURLを抽出する方法
- 【発展】正規表現を使って複数の異なる抽出対象を取得する方法
などの使い方に関して解説していきます。正規表現の抽出について正しく理解し、必要な場面で使いこなすことができるように、一緒に学習していきましょう!
なお、Pythonの記事については、こちらにまとめています。
正規表現の基礎を理解し、自在に使いこなせるようになることは、プログラミングスキルの向上に大いに役立ちます。しかし、独学での習得に不安を感じる方も多いのではないでしょうか。そんな時は、専門的なサポートを受けることで、効率的にスキルを磨くことができます。
実践的なスキルを身につけるための環境が整っている場では、AIを活用したWeb制作の具体的なノウハウを学ぶことが可能です。机上の空論ではなく、すぐに役立つ技術を得たい方は、ぜひセミナーの詳細を確認してみませんか?
正規表現とは
正規表現は、文字列の集まりを1つの形式で表すための特別な書き方になります。こちらの正規表現のサンプルを見てみましょう。
^[0-9]{3}-[0-9]{4}$
こちらのサンプルは、郵便番号を抽出するための正規表現になります。わかりやすく図で表したものがこちらになります。
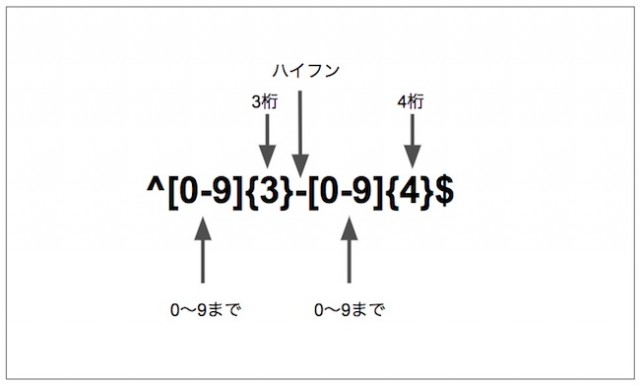
この正規表現を使うと、0〜9までの数字3桁で始まり、ハイフン(“-“)の後に同じく0から9までの数字4桁で終わる文字列を抽出することができます。Pythonには正規表現(regex)を扱うためのreモジュールが用意されています。
基本的にはそのreモジュールの関数の引数に、正規表現を渡すことで文字列の抽出などの操作ができるようになっています。これから、文字列を抽出することが出来る関数やメソッドを見ていきましょう!
正規表現の基本的な使い方
正規表現を使って文字列を抽出する方法
ここからは実際に文字列を抽出することが出来る関数やメソッドを紹介していきます。
先頭が一致する文字列抽出 match関数
match関数は、検索対象の文字列の先頭に抽出ワードが存在するか判定します。第一引数に抽出する正規表現、第二引数に検索対象の文字列を指定します。対象が存在しない場合はNoneを返し、存在する場合はmatchオブジェクトが返ります。
import re
address = "123-7777 東京都千代田区"
postCode = re.match('[0-9]{3}-[0-9]{4}' , address)
print (postCode)
実行結果
<_sre.SRE_Match object; span=(0, 8), match='123-7777'>
気をつけなければならないのは、文字列の先頭部分しか見てくれないという点です。よく利用されるケースとしては、検索したい文字が先頭にあることがルール上決まっている文字列を抽出する場合に有効です。
では次に、文字列全体を見てほしい場合は、次のsearch関数を使いましょう。
全体の中で一致する最初の文字列抽出 search関数
search関数は検索対象の文字列の先頭から最後までを検索し、抽出ワードが存在するか判定します。第一引数に抽出する正規表現、第二引数に検索対象の文字列を指定します。対象が存在しない場合はNoneを返し、存在する場合はmatchオブジェクトが返ります。
import re
address2 = "東京都千代田区 123-7777"
postCode = re.search('[0-9]{3}-[0-9]{4}' , address2)
print (postCode)
実行結果
<_sre.SRE_Match object; span=(8, 16), match='123-7777'>
先程のmatch関数とは郵便番号と住所が逆のaddress2という変数を用意しています。もし先程使ったmatch関数を使用すると郵便番号が先頭にないので、結果としてNone(該当無し)という結果が返ります。
search関数は先頭だけではなく文字列全体を検索したい時に有効な関数です。
全体の中で一致する文字全て抽出 findall関数
findall関数は検索対象の文字列の先頭から最後までを検索し、存在する正規表現の全てを取得して文字列のリストで返します。第一引数に抽出ワード、第二引数に検索対象の文字列を指定します。
import re
address3 = "東京都千代田区 123-7777, 東京都世田谷区 567-9999"
postCodeList = re.findall('[0-9]{3}-[0-9]{4}' , address3)
if postCodeList:
print (postCodeList)
実行結果
['123-7777', '567-9999']
郵便番号が2つに増えていますが、しっかりとリストに格納されていることがわかるかと思います。findall関数は、検索したい文字が有るか無いかだけではなく、有るもの全てを取得したい場合に有効な関数です。
抽出対象の場所を調べる findメソッド
findメソッドは文字列型のメソッドで、文字列を検索するときに使用します。たとえば、以下の文字列から「python」を検索したい場合は以下のようになります。
str = "Ruby,Python,PHP,Java,C"
fd = str.find('Python')
print(fd)
実行結果:
5
これは、検索対象の文字列の中にあるインデックス番号を示しています。findメソッドは検索対象の文字列の先頭から最後までを検索します。引数に渡した文字列が存在すれば、そのインデックスを返します。
インデックスとはリストや辞書などに含まれている要素の位置のことです。検索した対象が存在しない場合は、”-1″を返します。
address4 = "東京都千代田区 123-7777"
city = address4.find('千代田区')
print (city)
実行結果
3
インデックスは0から始まるため、千代田区の文字の始まり位置が”3″(0文字目から数えて3文字目)という結果が得られます。正規表現を使うことが出来ないので柔軟な検索は出来ません。
でも、文字列型で手軽に検索が出来るというのは大きな魅力ですよね。正規表現を使うほど幅広い検索パターンを意識する必要が無い場合には、findメソッドを使用してみると良いでしょう。
findメソッドについては、以下の記事でも詳しく解説していますので、ぜひ参考にしてください!

正規表現を使ってURLを抽出する
それでは正規表現を使った実践的な使い方を見ていきましょう。今回はURLを正規表現を使って抽出してみます。コードにはHTMLが登場しますが、HTMLがわからなくても理解できます。
今回使うURLの形式はこのような形で書かれています。
URL形式:products/[商品カテゴリー(英小文字1文字以上)]/[商品番号(4桁の数字)]/
例)https://exsample.com/products/mens/0001/
このURLがHTMLファイル内に記述されていると想定します。正規表現を使って抽出するサンプルコードを見てみましょう。
import re
html = """
<html>
<head></head>
<body>
<div id="item">
<a href="https://exsample.com/products/mems/7913/"></a>
</div>
<div id="item">
<a href="https://exsample.com/products/kids/8567/"></a>
</div>
</body>
</html>
"""
urlList = re.findall('https://exsample.com/products/[a-z]+/[0-9]{4}/' , html)
if urlList:
print (urlList)
実行結果
['https://exsample.com/products/mems/7913/', 'https://exsample.com/products/kids/8567/']
htmlという変数に、HTMLファイルが記述されていますね。ここからfindall関数を使ってhtml変数内のURLを抽出しています。商品カテゴリーを抽出する正規表現で、”+”は直前の文字(ここではaからzの英子文字)が1文字以上という指定を表しています。
正規表現を使った置換
ここまでは文字列の抽出方法について解説してきました。正規表現を使った文字列の抽出に並んでよく行われる操作が、文字列の置換です。文字列の置換が出来るようになると、柔軟に文章を作ることが出来るようになります。
詳しい解説は、こちらの記事をご覧ください。

正規表現のパターン一覧と簡単に表現する方法とは
正規表現のパターン一覧
これまでのサンプルコードの中で使用されてきた正規表現、[0-9]{3}-[0-9]{4} について、ここで詳しくご紹介します。この正規表現で使われている中カッコ{} やカギカッコ[]は、”メタ文字”と呼びます。
メタ文字は他にも様々な種類があり、全てを覚えるには時間が掛かります。ですので、あなたが実際に正規表現が必要になった時に辞書がわりに使えるようにと、以下に使用頻度が高いメタ文字の一覧を掲載しておきます。
この記事をブックマークなどで保存しておき、必要な時に調べられるようにしておくと良いでしょう。
| メタ文字 | 説明 | 使用例 | 合致する文字列 | 合致しない文字列 |
|---|---|---|---|---|
| . | 任意の1文字 | h.t | hat,hot,hit | head,height |
| * | 直前のパターンを0回以上繰り返す | 山川* | 山,山川,山川川 | 里 |
| + | 直前のパターンを1回以上繰り返す | gre*n | greeeeeeen | grn |
| ? | 直前のパターンを0もしくは1回繰り返す | 山川? | 山,山川 | 山川川 |
| {数字} | 直前のパターンを数字の分だけ繰り返し | 9{3} | 999 | 9,99,9999 |
| [文字,文字] | カッコ内の文字のいずれか1文字 | [a,b,c] | a,b,c | d,e |
任意の文字を簡単に表すために
先ほどご説明したメタ文字以外にも、任意の数字や文字を表すための正規表現固有の特殊文字があります。それが、特殊シーケンスと呼ばれる文字です。
| 特殊シーケンス | 説明 | 例 |
|---|---|---|
| \d | 任意の数字 | 1,2,3など |
| \D | 任意の数字以外 | a,b,abcなど |
| \w | 任意の英数字 | 1,2,333,ab,12abなど |
| \W | 任意の英数字以外 | 山、川、空白など |
上記の表を見ていただくとお分かりになる通り、特殊シーケンスはバックスラッシュ()と英字です。このバックスラッシュを英字とセットにして特殊シーケンスを表記する処理をエスケープ処理と呼びます。
このエスケープ処理があるおかげで、プログラムが”d”を見た時に、”d”という英字1文字を検索したいのか、任意の数字を検索したいのか区別することができます。
まとめ
この記事ではPythonの正規表現の抽出についてを解説しました。
- match関数
- search関数
- findall関数
- findメソッド
の特徴を踏まえて、文字列の抽出をしてみましょう。URLの抽出はとても実践的でしたが、これが理解できるとあとは正規表現の書き方を覚えるだけです。正規表現を使って抽出することを考える場面は今後も多く出てくると思います。
そのようなときはぜひこの記事を思い出し、読み返してみてください!
なお、今Pythonを学習している方は以下の記事もどうぞ。
はじめてPythonを使う方でもわかりやすいように、Pythonでできることやその学習法などを中心にまとめています。
復習にも使えると思いますので、ぜひ一度ご覧になってみてくださいね。
【Python 入門完全攻略ガイド】





