

DeepMindの囲碁ソフトAlphaGOや、プリファード・ネットワークス社の線画に色を付ける自動着色システムPaintsChainerなどでも使われているディープラーニング。
近年巨大で複雑なディープラーニングを使って、様々な問題の解決ができるようになってきました。
さて、ディープラーニングの計算は非常に計算が重く、普通のCPUだけで計算するととても時間がかかります。そんな中、現在のディープラーニングの計算の高速化にはGPU(Graphics Processing Unit)が使われています。
- 何故、GPUがディープラーニングに使われるのか
- GPUにはどのようなものがあるのか
この記事ではこのようなディープラーニングに関係するGPUの話をまとめました!
ディープラーニングの計算におけるGPUの重要性について理解が深まったでしょうか?「自分には少し難しいかも…」と感じた方には、AI技術を活用した新たなスキル習得の機会が役立つかもしれません。実践的なスキルを身につけることで、収入やキャリアの未来が広がります。
このセミナーでは、生成AIとWeb制作を組み合わせた収益化の具体的な流れを学べます。机上の空論ではなく、すぐに使えるノウハウを実践的に体験することができます。少しでも興味がある方は、セミナーの詳細を確認して、次のステップを探してみませんか?
なぜGPUが使われるのか

特徴の違い
CPUは高性能のコアが少数(通常4コア~64コア程度)載っているのに対し、GPUは比較的低性能のコアが大量(600~5000コア程度)載っているデバイスです。
ディープラーニングでは、行列計算を多用します。そしてこのような計算において、GPUは無類の強さを誇ります。
GPUはCPUのような柔軟な計算(条件分岐がたくさんあるような計算や、並列化ができない計算)は不得意ですが、そのかわりに単純な計算を並列で計算することが得意なんです。
この特徴がディープラーニングと相性がよく、尚且高性能なのに比較的安価であることも「深層学習するならGPU」ムードの追い風になりました。
CPUとGPUの性能比較
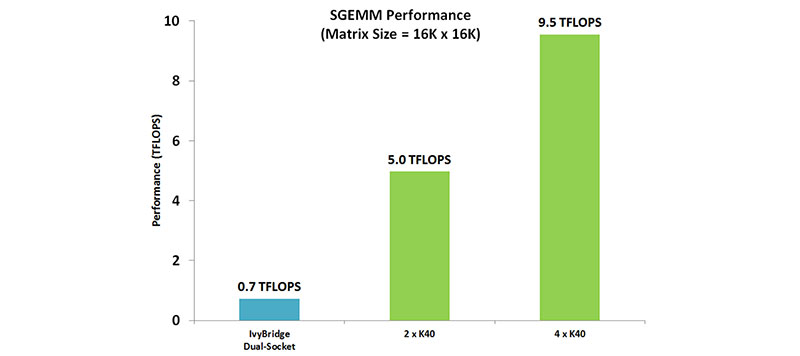
[画像:GPUアプリケーション 計算科学やエンジニアリングを変革する–NVIDIA]
GPUメーカーのNVIDIA社が公開している、機械学習アプリケーションのベンチマークのグラフです。
x軸はそれぞれ、
- IvyBridge Dual-Socket
- インテル製のCPUを二つ使った場合
- 2 × K40
- NVIDIA社製のGPUカードK40を二枚使った場合
- 4 × K40
- 同4枚使った場合
を示しています。
これに対してy軸は、これらのハードウェアの計算性能を示す値になっています。
TFLOPS(テラフロップス)という単位になっていますね。FLOPSというのはGPUなどの計算能力を表す単位で、値が大きい方が計算能力が高い、ということになります。
このグラフを見ると、2 × K40はCPUに比べて約7倍以上の性能を持っている事がわかります。このグラフを見るだけでも、GPUの計算能力の高さが伺えますね。
GPUの種類

NVIDIAとAMD
現在事実上、GPUのメーカーとして有名なのは二社、NVIDIAとAMDです。
NVIDIA製のGPUには大きく分けて3つのブランドがあります。
- GeForce(ジーフォース)
- 一般向け
- ゲーミング向け</li>
- Quadro(クアドロ)
- 業務用
- CADや3DCGモデリングなど向け
- Tesla(テスラ)
- 業務用
- GPGPU(General-purpose computing on graphics processing units; GPUによる汎用計算)向け
これに対しAMDは以下の通り。
- Radeon(レイディオン/ラデオン)
- GeForceの対抗馬
- Radeon Pro
- 業務用
- 最新のRadeon Pro WXは「ワークステーション向けGPU」と報道されている模様
- クリエイター向け
- Radeon Instinct
- 業務用
- 機械学習向け
一般の人が購入する機会があるのは、GeForceかRadeonでしょう。これらはゲーマーや科学計算用マシンを安価に組みたい人たちに人気です。
どちらかというと、AMDのグラフィックボードよりはNVIDIAのグラフィックボードの方が深層学習の分野では活躍しています。主要なDeep Learningフレームワークが対応するまでは、AMD製グラフィックボードでの深層学習は初心者には難しいかもしれません。
AMDも深層学習・機械学習の分野への対応を進めているので、今後の動向に注目です。
CUDAとOpenCL
GPUを使った計算を行うために、CUDAやOpenCLのようなGPGPU開発・実行環境が使われます。大雑把に言うと、CUDAはNVIDIAのGPUで使われるもので、OpenCLは様々なデバイスに対応しています。(もちろんAMDのGPUにも)
これらの言語はC言語の拡張ですが、PythonからDeep Learningを開発する人たちはあまり直接触ることは無いはずなので心配しないでください。
実はTensorflowやPytorch、Chainerなどの有名なDeep Learningフレームワークは内部でCUDAやOpenCLを使っています。
ユーザーが直接CUDA等を書かなくても良いように、フレームワークが(Pythonを書くだけで深層学習の実装が簡潔するような)機能を提供してくれているんですね。
そして、Deep LearningフレームワークのOpenCL対応が遅れているのに対して、CUDAは広く使われています。だから現状では、深層学習用のGPUと言ったらほぼ、NVIDIA製品となっているんですね。更に、CUDAやOpenCLで高速なプログラムを書くには、GPUの特性をしっかりと知っていないといけません。
その点、Pythonのフレームワークならば、そのアタリをあまり気にすることなく高速なプログラムが書けて便利なんです。Pythonの深層学習フレームワークについては、以下の記事でも詳しく解説してるので、是非読んでみてください。

また、フレームワークならば、勉強も比較的簡単です。
侍エンジニアのマン・ツー・マンレッスンでも学ぶことができます。
最新NVIDIA GPU
[リンク Geforce RTX 2080ti ]
2018/9/27、NVIDIAの最新グラフィックボード「Geforce RTX 2080ti」が発売されました。
(※GTXからRTXに名前が変わりました!)
また同RTX2080も発売され、新しいNVIDIA GPUのフラッグシップが徐々に解禁されて来ています。
RTXシリーズは
- 「リアルタイムレイトレーシング」
- 「AI強化グラフィックス」
などの新機能を備え、GTX1080tiよりも数段高性能であることを謳っています。
(Deep Learning分野のベンチマーク比較などを確認していないため、詳しい情報は後日更新します)
著者はRTXシリーズを持っておらず手元でのベンチマークはできませんが、以下のサイトでベンチマークが公開されているようです。
また、Deep Learningのベンチマークではないですが、ゲーマー向けの情報サイト「4Gamer.net」にRX2080tiの特徴や比較についてまとめられた記事が掲載されています。
更に10/17には、RTXシリーズ第三段のRTX 2070が国内発売され、徐々にGTX10X0シリーズの次の世代に、Deep Learning界隈も移行していくことになるでしょう。
これから新しいDeep Learningマシンを購入したいと考えている方々は、最新のRTXシリーズの購入も検討してみてはいかがでしょうか。
最後に
この記事では、深層学習の計算の高速化に必須のデバイスであるGPUについて紹介しました。深層学習の勉強をしているならば、たぶん多くの人が欲しくなるデバイスだと思います。
この記事で深層学習とGPUの関係を知って、勉強に役立ててくれると嬉しいです!
なお、Pythonをはじめて学ぶ方は、ぜひ以下の記事もご参考になさってください。
Pythonでできることや学習法を中心に、基礎知識をご紹介していますので、きっと参考になるかと思います。
【Python入門 完全攻略ガイド】





