

Deep Learningのフレームワークについて、以前紹介記事を書きました。

この記事では、その記事でも紹介した深層学習フレームワークの一つ、PyTorchについて紹介します!
Deep Learning研究の分野で大活躍のPyTorch、書きやすさと実効速度のバランスが取れたすごいライブラリです。
※ この記事のコードはPython 3.6, PyTorch 1.0で動作確認しました。
PyTorchの魅力に触れることで、Deep Learningの世界が少しずつ見えてきたかもしれません。しかし、技術の進化が早い現代において、AIスキルを独学でマスターするのは簡単ではありません。生成AIとWeb制作を組み合わせたスキルを身につけることで、収入源を多様化し、将来のキャリアをより安定させることができます。
このセミナーでは、実践的なノウハウを学ぶことで、すぐに使えるスキルを手に入れることが可能です。案件獲得から納品までの具体的な流れを知ることで、AIを活用した収益化の道が開けます。少しでも興味がある方は、詳細を確認して自分に合った学びのスタートを切ってみませんか?
PyTorchとは

PyTorchの特徴
PyTorchは、Python向けのDeep Learningライブラリです。
Facebookが開発を主導し、その書きやすさと使いやすさから人気があります。
このライブラリは非常に柔軟なニューラルネットワークの記述ができ、今主流であるDeep Learningライブラリの中でもかなりの人気を誇ります。
公式ページのaboutによると
- 強力なGPUアクセラレーションによるテンソル計算
- (リバースモードの)自動微分を使いシンプルなニューラルネットワークの記述が可能
などの特徴を持ちます。
Deep Learningの世界ではGPUを使ったアクセラレーション(高速化)は必須です。これは有名なDeep Learningフレームワークならば殆どが備える機能です。
また、自動微分についても同様です。
このPyTorchはNumpy、Scipy、Cythonなどの、Pythonでの科学計算でよく使うライブラリによって拡張することができます。
そのため、細かいところまでPythonでカスタマイズする事ができます。最新のDeep Learningモデルを実装するにはうってつけのライブラリですね。
また、Chainerという国産ライブラリに非常に似た使い心地なので、Chainerを使ったことがあるユーザーならば簡単に習得することができるでしょう。
PyTorchは人気のフレームワーク
Githubでの注目具合を見てみましょう。
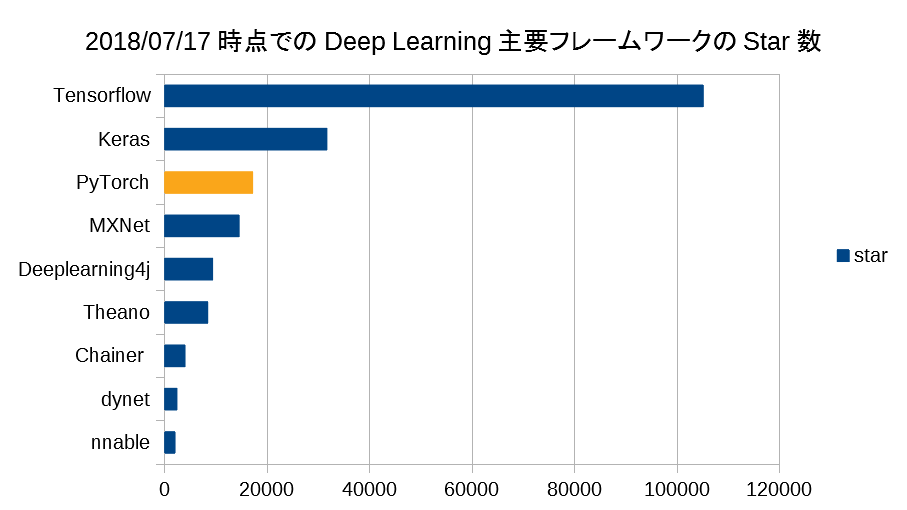
このグラフは、「Deep Learningの主要フレームワーク」のGithub Star数です。
Tensorflow、Kerasに続き第三位の位置にあります。PyTorchはTensorflowに比べてやや後発なのですが、健闘していますね。
TensorflowがGoogleの強力なバックアップで開発と宣伝が進められている点を考慮すると、PyTorchの人気具合がわかるかと思います。
教材の豊富さ
PyTorchの解説動画も大量にあるので、勉強も比較的容易です。
また、書籍も数多く発表されています。
[つくりながら学ぶ! 深層強化学習 ~PyTorchによる実践プログラミング~ 単行本(ソフトカバー) – 2018/6/28 株式会社電通国際情報サービス 小川雄太郎 (著)]
[PyTorchで始める深層学習 ――数式なしで基礎から実装まで 単行本(ソフトカバー) – 2018/5/21 小泉 訓 (著)]
PyTorchはその習得のしやすさや、研究開発との親和性の高さから、発表されてすぐに世界中で人気になりました。
PyTorchのインストール
PyTorchのインストール方法は、公式ページにかかれています。

Get Started.の右側にあるボタンは以下の手順で選択しましょう。
- PyTorch Build
- 安定版かプレビュー版かを選びます。
- 普通は安定版でOKです。
- Your OS
- PyTorchをインストールしたいPCのOSを指定しましょう。
- Package
- 普通はpip、Anacondaを使っている場合はcondaを選択しましょう。
- Language
- PyTorchを使うプログラミング言語を選びます。以前はPythonだけでしたが、C++が追加されました。
- Pythonを使う場合は端末エミュレータで「Python -V」と打つとバージョンが確認できます。
- CUDA
- NVIDIAのGPUを使っている人はCUDAのバージョンを指定します。
- GPUがない場合はNoneを選択します。
自分の開発環境にあったボタンを押すと、その条件にあったインストールコマンドが「Run this command:」の横に表示されます。コピーして端末エミュレータで実行するとインストール作業が始まります。
PyTorchのコード
Define by Run
PyTorchはDefine by Run式のライブラリです。
簡単に言うと、「Pythonコードをそのまま書くだけでDeep Learningモデルが実装できる」タイプのライブラリになります。また、Deep Learningの実装では、多くの場合モデルの訓練に偏微分が必要になります。
微分の計算も、ニューラルネットワークモデルが複雑になると大変になります。それこそ人の手でいちいち微分をしていては追いつかない程に。
PyTorchでは、他の多くのDeep Learningフレームワークと同様に、自動微分機能がついています。PyTorchの関数を使って実装している限り、ニューラルネットワークのバックプロパゲーションについて実装する必要はありません。
モデルの実装と、損失関数の定義までを行ってしまえば、バックプロパゲーションの計算を自動で行ってくれます。

上のgifを見ると、変数lossに損失関数が入っていて、その損失関数をloss.backward()するだけで勾配が計算できるとあります。
実際のコード
PyTorchで実際に、簡単な三層のニューラルネットワークを実装してみました。
Jupyter上で実行して見てください。
ライブラリのimport
import torch import torch.nn as nn from torchvision import datasets import torchvision.transforms as transforms from torch.autograd import Variable import matplotlib.pyplot as plt % matplotlib inline
ハイパーパラメータの設定
# Hyper Parameters input_size = 784 hidden_size = 500 num_classes = 10 num_epochs = 5 batch_size = 100 learning_rate = 0.001
データセットの用意
torchvision.datasetsからMNISTという手書き文字認識のデータセットを利用します。
# MNIST Dataset
train_dataset = datasets.MNIST(root='../data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='../data',
train=False,
transform=transforms.ToTensor())
Output:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz Processing... Done!
minibatch学習の準備
学習は通常、minibatch単位で行います。
学習の際にminibatchをデータ全体から切り出してくれるクラスを定義しておきましょう。
# Data Loader (Input Pipeline)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
ニューラルネットワークの定義
PyTorchを使ったニューラルネットワークの定義は非常に見やすいものになります。
Chainerを使ったことがある方には、わかりやすいのではないでしょうか。
# Neural Network Model (1 hidden layer)
class Net(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
モデルインスタンスの作成
ニューラルネットワーククラスからインスタンスを作ります。
この際にGPUを使うのであれば、ネットワークインスタンス.cuda()としてGPUで実行できる形にしておきましょう。
net = Net(input_size, hidden_size, num_classes) net.cuda()
Output:
Net( (fc1): Linear(in_features=784, out_features=500, bias=True) (relu): ReLU() (fc2): Linear(in_features=500, out_features=10, bias=True) )
損失関数とオプティマイザの設定
ここでは例としてMNISTの分類を行うので、損失関数としてクロスエントロピーを使います。
オプティマイザは様々ありますが、Adamを使ってみます。
# Loss and Optimizer criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate)
トレーニング
ネットワークの訓練を行う関数を定義して、これを走らせてみましょう。
ここについてはもっとスマートな書き方がありますが、今はシンプルに一般的なネットワークのfit関数を書いてみます。
def fit(net, train_loader, num_epochs=num_epochs, t= 200):
# モデルのトレーニング
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# pytorchのtensorをVariableに変換
images = Variable(images.view(-1, 28*28)).cuda()
labels = Variable(labels).cuda()
# フォワードプロパゲーション/ バックプロパゲーション/ 最適化
optimizer.zero_grad() # 勾配を0初期化
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# t回毎にログを表示
if (i+1) % t == 0:
print ('Epoch [%d/%d], Step [%d/%d], Loss: %.4f'
%(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.data.item()))
return net
net = fit(net, train_loader)
Output:
Epoch [1/5], Step [200/600], Loss: 0.3556 Epoch [1/5], Step [400/600], Loss: 0.1908 Epoch [1/5], Step [600/600], Loss: 0.1428 Epoch [2/5], Step [200/600], Loss: 0.1996 Epoch [2/5], Step [400/600], Loss: 0.1316 Epoch [2/5], Step [600/600], Loss: 0.0717 Epoch [3/5], Step [200/600], Loss: 0.0298 Epoch [3/5], Step [400/600], Loss: 0.0345 Epoch [3/5], Step [600/600], Loss: 0.0895 Epoch [4/5], Step [200/600], Loss: 0.0205 Epoch [4/5], Step [400/600], Loss: 0.0703 Epoch [4/5], Step [600/600], Loss: 0.0191 Epoch [5/5], Step [200/600], Loss: 0.0310 Epoch [5/5], Step [400/600], Loss: 0.0349 Epoch [5/5], Step [600/600], Loss: 0.0399
評価
モデルを評価してみます。
訓練に使ったデータとは別のデータ(テストデータ)を使って、未知のデータをどのくらい正確にクラス分類できるのか確かめます。
def evaluate(net, test_loader=test_loader):
# Test the Model
correct = 0
total = 0
for images, labels in test_loader:
images = Variable(images.view(-1, 28*28)).cuda()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted.cpu() == labels).sum()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
evaluate(net)
Output:
Accuracy of the network on the 10000 test images: 97 %
もっと複雑なDeep Learningモデルの実装も、PyTorchならば美しく実装できるでしょう。
本腰を入れてPyTorchとDeep Learningを勉強したいならば、侍エンジニアのマンツーマンレッスンを受講してみてください。
深層学習に詳しいエンジニアがインストラクターになって、あなたの勉強をサポートします!
まとめ
この記事では、PyTorchについてまとめました。
PyTorchは近年の複雑なDeep Learningモデルの実装に適した、非常に柔軟なDeep Learningフレームワークです。
速度もあり、GPUへの対応も簡単です。Deep Learningの勉強を始めるには最適のフレームワークなので、是非とも使ってみてくださいね。




