

ビッグデータやAIが話題になっている昨今ですが、膨大なデータを効率的に扱うために行うための処理の一つに「次元圧縮」があります。
データ一つ一つが数万個の特徴を持っているとしましょう。その特徴すべてをそのままデータ解析に使う必要があるのでしょうか?
もしかしたら、他の特徴と似たような特性を持っている特徴がたくさんあるかもしれません。また、特徴が増えれば増えるほど、必要となるメモリが増えてしまいます。計算機資源の面から言っても、次元圧縮を行うことは有用だといえます。
この記事では「主成分分析(PCA)の大まかな概要とscikit-learnによる実装」を解説します。PCAの勉強を始める前に、まずはどんな事ができるのかを確かめておきましょう。
主成分分析(PCA)とは
次元圧縮の手法「主成分分析」について簡単に紹介します。
PCA(Principal Component Analysis、主成分分析)とは、
- 機械学習(教師なし学習)の一つ
- 次元圧縮手法
- データのばらつき具合に着目して新しい座標軸を作る
- ばらつき具合(=分散)が大きいところが大切
のような機械学習モデルです。
PCAは大量の特徴を持つデータに適用することで、比較的少数の項目に置き換えます。もともとあった特徴を新しい座標軸を使って少ない次元で表現します。
- 100次元を5次元へ圧縮
- 4次元を3次元へ圧縮
のような変換を行い、教師あり学習の入力データを作ったり、データの可視化を行ったりします。
PythonでPCA
PythonでPCAを試してみましょう。勉強のために自分で実装してもいいのですが、この記事では簡単のためにscikit-learnを使ってPCAを試します。
OS: Windows 10
Python: 3.6.5
まずはライブラリをimportしましょう。
import numpy as np # Pythonで機械学習をするならとりあえずimport from sklearn.decomposition import PCA # 今回の主役。scikit-learnのPCAクラス from sklearn import datasets # デモ用のデータセットを読み込むモジュール import seaborn as sns # 可視化用のライブラリ import pandas as pd # 便利なDataFrameを使うためのライブラリ import cufflinks as cf # おしゃれな可視化のために必要なライブラリ その2 cf.go_offline() # cufflinksをオフラインで使うため
次に、データセットを読み込みます。
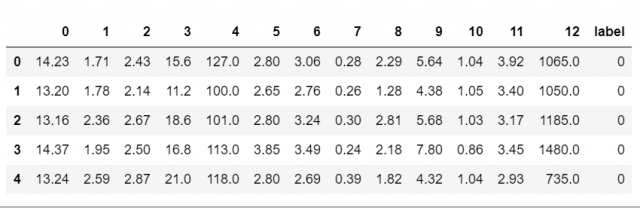
wine = datasets.load_wine() # wineデータを読み込み df = pd.DataFrame(wine.data) # DataFrame形式に変換 df["label"] = wine["target"] # データのクラスをDataFrameの列の一つとして追加 df.head() # 試しにDataFrameの先頭5行を表示してみましょう
[出力結果]
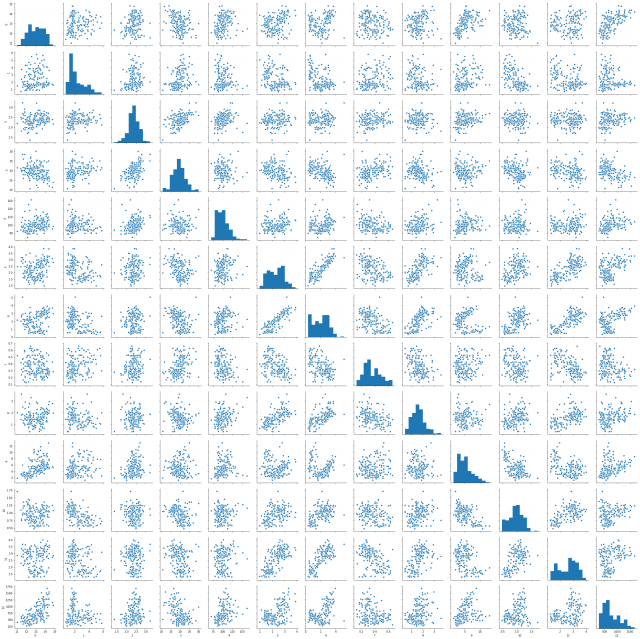
PCAをする前に、このデータセットをsns.pairplotで可視化してみましょう。このとき、データセットを読み込むときにクラスを列に追加したのを思い出して下さい。
そのままsns.pairplotに渡してしまうと、クラス情報まで特徴と同じように扱われてしまいます。
sns.pairplot(df.iloc[:,:-1]) # df.iloc[:, :-1]にすることですべての行の
# 最後の列以外を指定して可視化します
[出力結果]
ではこれをPCAにかけてみましょう。
pca = PCA(n_components=3) # 3次元に圧縮するPCAインスタンスを作成 X = pca.fit_transform(df.iloc[:,:-1].values) # wineデータをPCAで次元圧縮 embed3 = pd.DataFrame(X) # 可視化のためにデータフレームに変換 embed3["label"] = df["label"] embed3.head() # データフレームの先頭を表示
[出力結果]
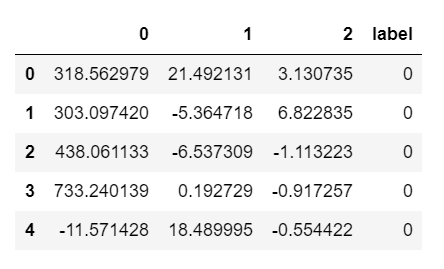
出力結果の表を見てみると、確かに三次元に圧縮できていることがわかりますね。
PCAの見方
圧縮して3次元の行列になったデータを三次元散布図としてプロットしてみましょう。
embed3.iplot(kind="scatter3d", x=0,y=1,z=2,categories="label")
[出力結果]
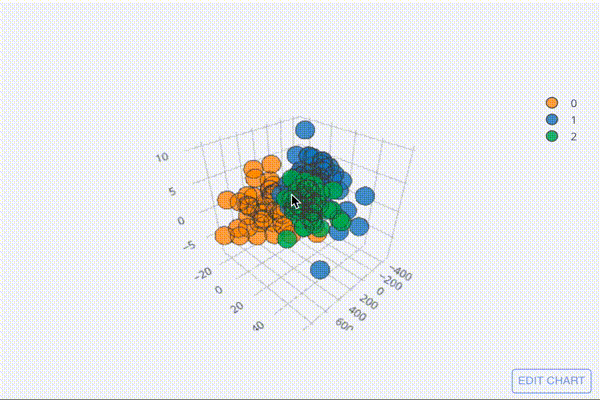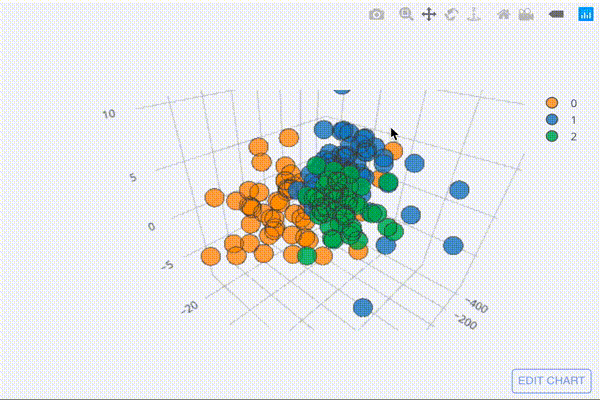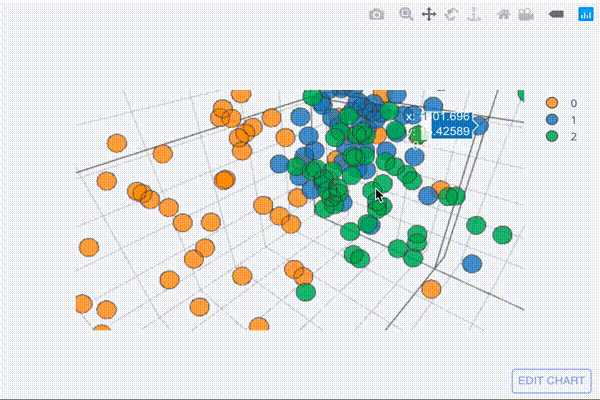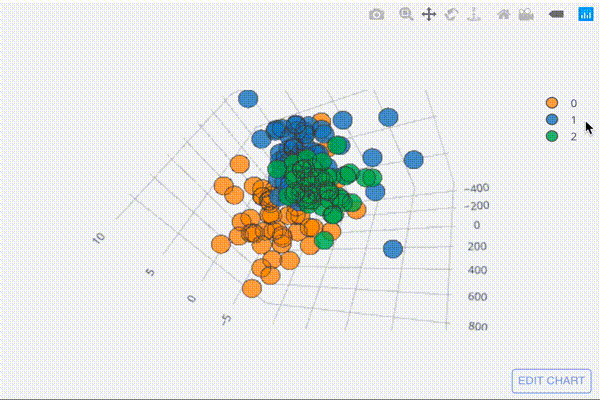
グリグリ動かしてどんな形になったのか確認してみてください。
ここまでできたら、次は以下のコードで2次元に圧縮してみてください。
PCA(n_components=2).fit_transform(df.iloc[:,:-1].values)
このように可視化のために使うこともできるPCA、本当はもっとたくさんの情報がわかります。これについてはまた次回。
まとめ
この記事ではPCA(主成分分析)について解説しました。
PCA以外にも次元圧縮を行うモデルはたくさんあります。AutoEncoder, SVD…などなど。データの種類や次元圧縮を行う目的によって使うべきモデルは異なりますが、PCAはその中でも覚えておきたいモデルの一つです。
sklearnを使えば簡単に使うことができます。是非試してみて下さい。




