

侍では、以下のようなpandasの使い方をまとめた記事を公開しています。
- 「pd.DataFrame/pd.Seriesの作り方まとめ」
- 「pandasによる可視化」
- 「pandasによる統計量の計算とデータの前処理」
- 「pandasのまとめ」
インタビューを読んで、同じような経験をしたいと思った方へ
どうやって勉強すればきちんと身につけられるんだろう…
初めてプログラミングに触れる方は、こんな疑問や不安を抱えている人も多いと思います。まずは気軽に、『無料カウンセリング』であなたのキャリアや勉強方法について一緒に考えてみませんか?
侍エンジニア
無料カウンセリングの詳細はこちら
この記事では、Pandasのplotを使ったDataFrameの可視化を紹介します。pandasの提供するデータ形式、「DataFrame」を使って、簡単にデータの可視化を行う方法を学んで行きましょう。
pandasによる可視化とは
pandasはPythonでデータ解析を行うために、統計処理や可視化を効率的に行うデータ形式
- Series
- DataFrame
- Panel
を提供します。特にDataFrameに着目して解説しますが、DataFrameに収められたデータを可視化するには、pd.DataFrameオブジェクトのplotメソッドを使います。
plotメソッドでは、kindという引数に作りたいグラフの種類を指定することで、簡単に様々なプロットができます。kindの種類は以下の通りです。
| – ‘line’ : line plot (default)
| – ‘bar’ : vertical bar plot
| – ‘barh’ : horizontal bar plot
| – ‘hist’ : histogram
| – ‘box’ : boxplot
| – ‘kde’ : Kernel Density Estimation plot
| – ‘density’ : same as ‘kde’
| – ‘area’ : area plot
| – ‘pie’ : pie plot
| – ‘scatter’ : scatter plot
| – ‘hexbin’ : hexbin plot※引用:help(df.plot)
詳しくはhelp(df.plot)を参照して下さい。
また、この方式に似た使い心地を踏襲して、裏で使っている可視化ライブラリを別のものに変えたメソッドを追加するライブラリ(cufflinks)もあります。
df.plotによる可視化
まずは基本になるplotメソッドを紹介します。
importとデータ作成
importするライブラリは以下の通りです。
import pandas as pd from sklearn import datasets import seaborn as sns sns.set()
必要なのは上の二行です。seabornはsns.set()でプロットの見た目をかっこよくするためだけに使っています。
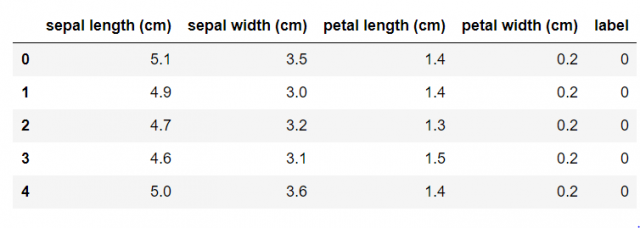
次に、可視化するデータをDataFrameにしましょう。ここではirisデータセットを使います。
iris = datasets.load_iris() df = pd.DataFrame(iris.data) df.columns = iris.feature_names df["label"] = iris.target df.head()
[出力結果]
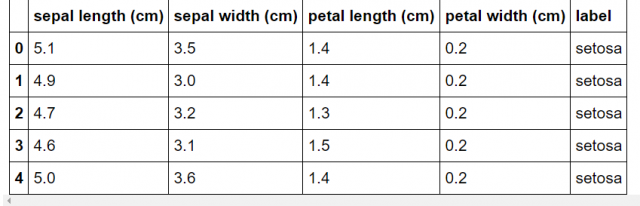
また、labelを数字にしておくと分かりづらい場合があります。数字ではなく、本来のlabelの名前に変更したバージョンのデータフレームも作っておきましょう。
df2 = df.copy() df2["label"] = [iris.target_names[i] for i in iris.target] df2.head()
[出力結果]
これで準備完了です。
折れ線グラフ
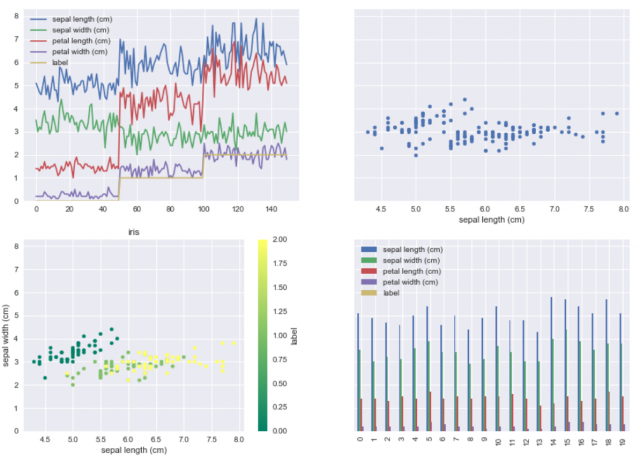
df.plot()
[出力結果]
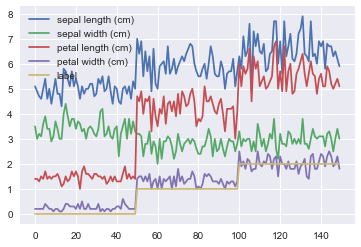
これが最も簡単なプロットです。df.plotは何も指定しない場合、このようなプロットになります。
この場合、データフレームの各列が折れ線になっています。labelを数字のままにしているので、labelも一緒に表示されている点に注意してください。これから様々なオプションを指定してかっこいいグラフを作る方法を試していきましょう。
散布図
散布図はkind=”scatter” と指定します。このとき、最低限の引数としてxとyを指定してください。
df.plot(
kind="scatter", # グラフの種類を指定
x=0, # x軸に対応する列の番号か列名
y=1, # y軸に対応する列の番号か列名
c="label", # 点の色を指定する列の番号か列名
cmap="summer", # 色合いの指定
title="iris" # プロットのタイトル
)
[出力結果]
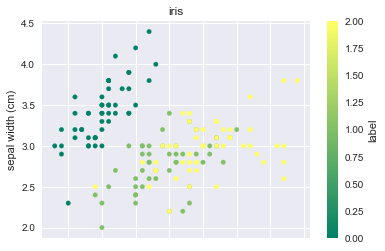
棒グラフ
棒グラフはkind=”bar”と指定します。
df2[:20].plot( # データ数が多いので上から20個だけ使います
kind="bar", # グラフ種類
figsize=(10,10), # グラフのサイズを指定します。
subplots=True, # Trueにするとグラフが要素ごとに別々に描画されます。
layout=(2,2) # グラフのlayoutを指定します。グラフの数を考慮してください。
)
[出力結果]
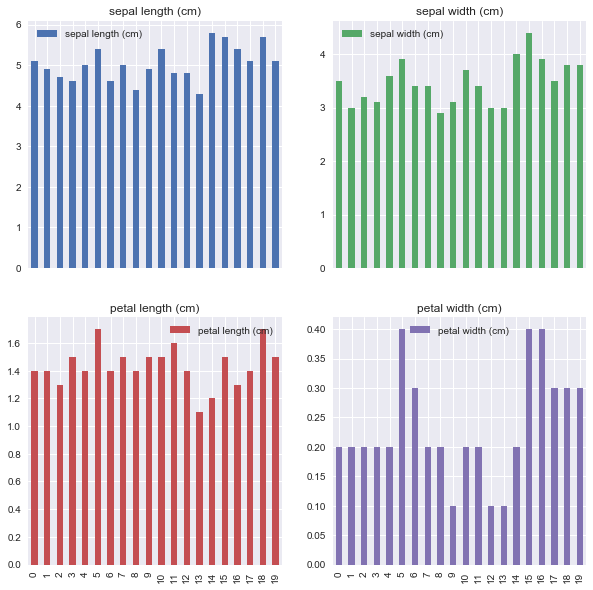
ヒストグラム
ヒストグラムも簡単に作れます。kind=”hist”と指定しましょう。
df2.plot(
kind="hist", # グラフの種類
figsize=(10,6), # プロットのサイズ(お好みで)
alpha=0.7 # 透過させる場合は適当な数字を指定しましょう。
)
[出力結果]
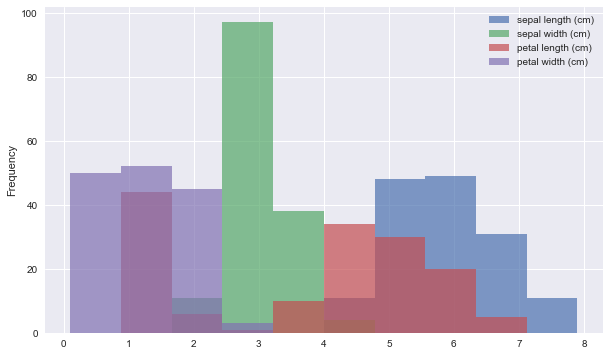
df.iplotによる可視化
df.plotと似たインターフェイスで可視化を行うメソッドとして、iplotがあります。iplotを使うと、plotlyという可視化ライブラリを使ったプロットが作成できます。
このiplot、使うにはまず、cufflinksというライブラリをimportする必要があります。このcufflinksがDataFrameにiplotメソッドを追加してくれます。これについては、以前書いたplotlyの記事で紹介しています。

seabornによる可視化
pd.DataFrameのインスタンスを引数に取る可視化ライブラリとして、seabornがあります。
seabornはPythonのデファクトスタンダード(事実上の標準)可視化ライブラリであるmatplotlibをベースにしたライブラリです。seabornについては、以下の記事で詳しくまとめています!

まとめ
この記事では、pandasによる可視化についてまとめました。
更にpandasを使ったデータ解析について勉強したいときは、侍エンジニアのマンツーマンレッスンに挑戦してみて下さい。この記事で紹介したpandasは非常に便利なライブラリです。
pandasをベースにして、様々な処理を手軽に行える環境を提供してくれます。もしもpandasを使った可視化で忘れてしまったことがあったら、是非この記事を思い出してくださいね!




