

機械学習手法の分類の一つに「クラス分類」があります。
ラベルのつけられたデータから法則を学習して、ラベルのないデータのラベル付けを自動で行う方法です。
この記事で
- クラス分類とは?
- クラス分類とクラスタリングの違いとは?
と基本的な内容を理解しましょう。
そして、その発展として
- クラス分類手法k-nnをscikit-learnで試してみる
ところまで行います。
機械学習入門者必見!この記事でクラス分類の仕組みの理解と実装に挑戦しましょう1
クラス分類の基本を理解し、scikit-learnを使った実装に挑戦することで、機械学習の世界に一歩踏み出すことができます。しかし、技術を習得するだけでなく、それをどのように収益化に繋げるかも重要です。もし「技術を活かして収入を得る方法をもっと知りたい」と思ったなら、実践的なスキルを学べる環境を活用するのも一つの方法です。
この環境では、生成AIとWeb制作を組み合わせた収益化の具体的な流れを学べます。机上の空論ではなく、実際に使えるノウハウが凝縮されています。少しでも興味がある方は、セミナーの詳細を確認して、自分に合った方法を探してみませんか?
クラス分類とは?

クラス分類
クラス分類とは機械学習の目的別の分類の一つです。
教師データ(ラベルとデータのセットがたくさんあるもの)を使って、データに対してそれぞれのデータがどのクラスに分類されるのか学習します。
学習の結果として見つかった法則性を元にして、テストデータ(ラベルがわからないデータ)にラベルづけを行います。
つまりクラス分類は教師あり学習の一部です。
クラス分類とクラスタリング
クラス分類と混同されるものにクラスタリングがあります。
クラスタリングは教師なし学習の一部です。
ラベル付のされていないデータに対して、データから法則性を学んで複数のクラスタ(データのまとまり)を作ります。
クラスタリングをラベルのあるデータに対してやってみると、
人間が作ったクラス(これもデータのまとまりのことです。ただし人間がラベル付したものですね)とクラスタでは違うまとまりになっていることがわかります。
どちらが良いとは言い切れませんが、クラス分類とクラスタリングは別物だと捉えてください。
クラスタリングについては以下の記事で解説しています。是非チェックしてください!

クラス分類の代表的な手法
クラス分類は様々な機械学習モデルで行うことができますが、有名なところでは
| 名前 | 略称 | 日本語名 |
| k-nearest neighbor algorithm | k-nn | k近傍法 |
| decision tree | 決定木 |
などがシンプルで広く使われています。他にも、Support Vector Machine (SVM)やニューラルネットワークなどでも行うことができます。
k-nn(k近傍法) の実装

この章ではsklearnを使ってk-nnをテストします。
この章で使っている問題は全てJupyter NotebookやJupyterlabで動かしています。
以下のコードをJupyterで実行しながら勉強していきましょう。
k-nnとは
k-nnはクラス分類の最もシンプルな実装の一つです。
ここで、二種類クラスを持ったデータ(■と▲)あるとしましょう。
k-nnでは、クラス分類をしたいデータ★から近い順にk個(k=1 or 3 or …)のクラスを見て、クラス分類を行います。
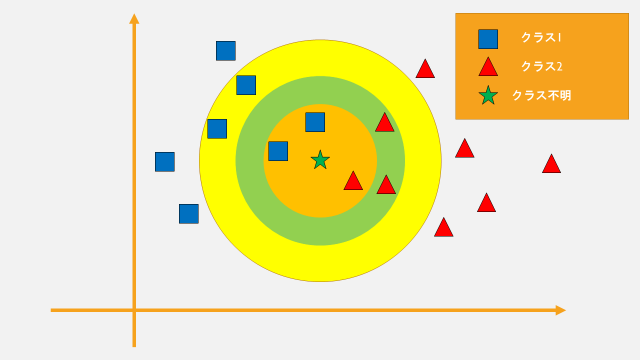
例えば、k=3のとき、オレンジ色の円の中のデータが対象になりますね。
この時は■が2個、▲が1個なので、★はクラス1に割り当てられます。
さらにk=7のとき、黄緑色の円の内側(オレンジを含む)が対象になります。
この時は、■は3個、▲は4個なので★はクラス2になります。
最後に、k=11のとき、黄色の円の内側(オレンジ、黄緑を含む)が対象になります。
この時は、■は6個、▲は5個なので★はクラス1になります。
この方法ならば、クラスの数が3以上になってもクラス分類が簡単ですね。
実験に使うデータ
このk-nnをPythonで実装してテストするために、クラス分類を行うデータを確認します。
この記事では、機械学習の世界で広く使われているiris datasetを使います。
irisの各データは4つの特徴を持っています。
データは全部で150個あるので、つまり150 x 4の行列がこのデータセットには格納されています。
irisは全部で3つのクラスを持っています。つまり三種類の花の特徴が収められたデータセットだということになります。
では実際のデータを見てみましょう。
JupyterlabやIPythonで、以下のコードを実行します。
import seaborn as sns
data = sns.load_dataset("iris")
# ちなみにこのirisはpandasのdataframeです。
data.head(20)
するとjupyter notebook上に下のような表が出てきます。
これで大体のデータの形がわかりますね。
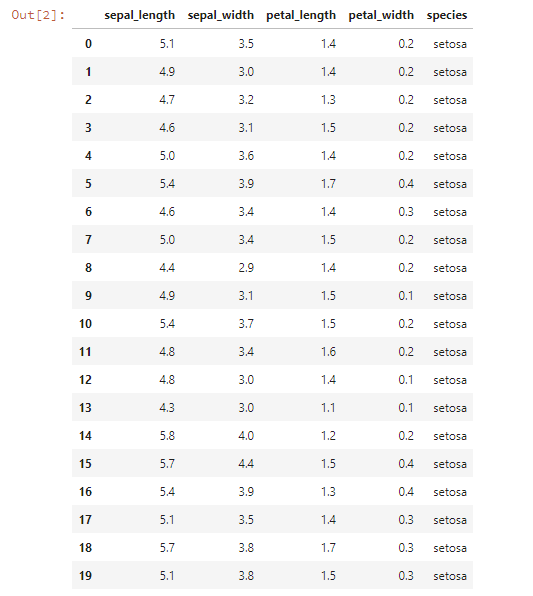
この表では0から19までのデータしか表示されていませんが、実際には150個のデータがあります。
次に、4つある特徴から2つずつ取り出してデータを可視化してみます。
sns.pairplot(data, hue = "species", diag_kind="kde")
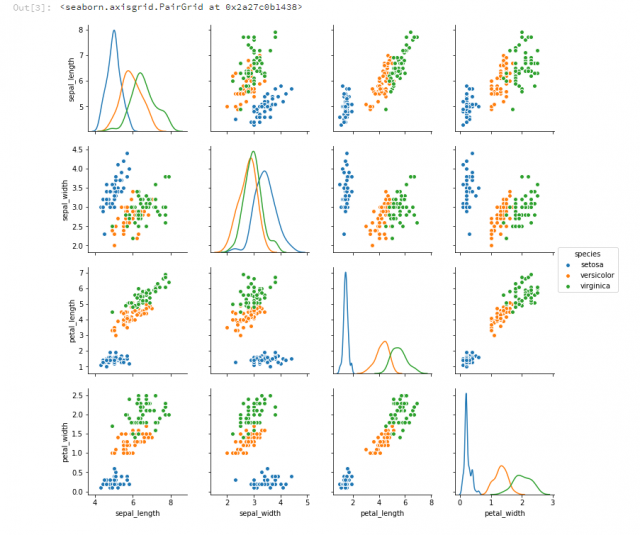
青いクラス(setosa)とそれ以外との分類は簡単そうですね。
このirisデータはデータ数が小さく、クラス分類の難易度が低いので学習用に広く使われています。
これから機械学習の勉強をしていくにあたって、このデータは使い勝手が良いので覚えておいてください。
教師データとテストデータを用意する
データセットを教師データとテストデータの2つに分割します。
データセットをシャッフル
データの順番をぐちゃぐちゃにしておかないと、データの順番から法則性を学んでしまうような手法もあるかも知れません。
data = data.sample(frac=1).reset_index(drop=True) data.head()
まずはこれで安心です。
教師データとテストデータの境目を決める
ここでは全体の80%を教師データ、20%をテストデータにします。
use_row_limit = int(data.shape[0] * 0.8)
f"全データが{data.shape[0]}個、そのうち{use_row_limit}個目までを教師データとして使う"
[出力結果]
'全データが150個、そのうち120個目までを教師データとして使う'
できるならば、クラスごとに教師データの数は均等になれば嬉しいです。
ここではカンタンのために気にせず全部ぐちゃぐちゃです。
ついでに、irisの入っているデータフレームの特徴を表す列番号も確認しておきましょう。
use_column=list(range(data.shape[1]))[:-1]
f"全列が{data.shape[1]}個、そのうち{use_column}番目にあたる列が特徴にあたる"
[出力結果]
'全列が5個、そのうち[0, 1, 2, 3]番目にあたる列が特徴にあたる'
教師データを切り出す
では実際に教師データを作ります。
ilocはdataframeから必要な部分を切り出すための機能です。
スライスの仕方はリストに似ていますね。
train_data = data.iloc[:use_row_limit,:] print(train_data.shape) train_data.head()
テストデータを切り出す
同様にしてテストデータも作っておきましょう。
test_data = data.iloc[use_row_limit:,:] print(test_data.shape) test_data.head()
さてこれで準備完了です。
k-nnのPython実装
sklearnのKNeighborsClassifier(k-nn)でクラス分類を行います。
まずはimport。
from sklearn.neighbors import KNeighborsClassifier as KNN
次に、データに適した設定をしたKNNのインスタンスを作ります。
ここで、KNNの引数は
- n_neighbors: k近傍のkの値
- n_jobs: k-meansを何並列にするか(-1ならばpcのコア数分だけ並列してくれます)
が重要です。
knn = KNN(n_neighbors=3, n_jobs=-1)
さらに、教師データをknnにセットします。
knn.fit(
X = train_data.iloc[:,use_column].values,
y = train_data["species"].values,
)
[出力結果]
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=-1, n_neighbors=3, p=2,
weights='uniform')
さて、この次がようやく本番。
テストデータをクラス分類します。
pred_target =knn.predict(
X = test_data.iloc[:,use_column].values,
)
pred_target
[出力結果]
array(['versicolor', 'virginica', 'setosa', 'virginica', 'virginica',
'virginica', 'setosa', 'versicolor', 'virginica', 'virginica',
'setosa', 'versicolor', 'versicolor', 'setosa', 'virginica',
'setosa', 'versicolor', 'virginica', 'virginica', 'virginica',
'virginica', 'versicolor', 'setosa', 'virginica', 'versicolor',
'setosa', 'virginica', 'setosa', 'versicolor', 'virginica'],
dtype=object)
このpred_targetというのがテストデータに対してknnが予測したクラスです。
これがどのくらい合っているんのか認識率(acc)を計算することで確かめましょう。
# acc: 認識率 sum(test_data["species"] == pred_target) / len(pred_target)
[出力結果]
0.9333333333333333
93%以上が正しくクラス分類できていることがこの数字からわかりました。
これはk-nnがすごいというよりも、iris datasetがカンタンなデータセットであることが大きな原因でしょう。
別のデータも使って確かめてみてください。
クラス分類を更に学ぶには

クラス分類の方法はここで紹介したk-nn以外にもたくさんあります。
より高精度の分類を求める場合などは、Deep Learningを使ったものもありますし、なかなかに奥の深い分野です。
画像分類ではDeep Leaarningの中でもCNN(畳み込みニューラルネットワーク)をベースにしたモデルが強力ですし、対象のデータによっても適切なモデルは代わりますね。
侍エンジニアでは、マン・ツー・マンレッスンでこのような機械学習の手法についてもレッスンを行っています。
[su_button url=”https://lp.sejuku.net/lp1_blog_01/?cid=ai_btn1_60536″ target=”blank” background=”#409fdf” color=”#fff88f” size=”10″ center=”yes” radius=”10″ icon=”icon: external-link” icon_color=”#fff88f” text_shadow=”0px 0px 10px #808080″]侍エンジニアとは?
詳細はこちらから[/su_button]
もっと機械学習、クラス分類を学びたい!という方は是非、侍エンジニアでマン・ツー・マンレッスンを受講してみてください!
まとめ
この記事では機械学習によるクラス分類の解説、特にk-nnのPython実装について解説しました。
クラス分類は機械学習分野でよく行われるタスクの一つです。
最も基本的なアルゴリズムであるk-nnを理解したら、次は更に強力なアルゴリズムに挑戦してみてください!




