

先日、sequence to seuqence(seq2seq)モデルを扱うTensorFlowのチュートリアルが、実は2017年に更新されていたという噂を聞きつけました。
そこで今回は、
・そもそもseq2seqって何?
・TensorFlowのseq2seqって、英語-フランス語のアレでしょう?
というあなたにこそ、読んでもらいたい記事を書きました。
seq2seqの概要と、新しいseq2seqのチュートリアルをWindows 10で動かすための手順を説明する記事になっていますので、ぜひ手元で動かしてくださいね。
seq2seqとは
seq2seqは、「語句の並び」を入力して、別の「語句の並び」を出力する(置き換える)ルールを学習するモデルです。
たとえば、英語をベトナム語に置き換えたり(翻訳)、質問を回答に置き換えたり(対話)、といったことに利用できるモデルです。
英語からベトナム語に翻訳する場合は、英語1文に対し、同じ意味のベトナム語1文をセットで学習して、文章の対応を学習します。
対話する場合は、質問1文に対し、回答1文をセットで学習するというわけですね。
また、機械学習の際は「語句の並び」は数値に変換されるため、これを応用して(語句の並びの代わりに)画像を入力して、語句の並びを出力する(=画像の説明を作成する)というルールも学習できます。
機械翻訳で有名なGoogle翻訳は、seq2seqモデルを応用して作成されています。
今や、データと十分な性能のコンピュータさえあれば、Google翻訳のようなモノを作ることは不可能ではなくなっているのです。
タスクを確認しよう
※2018年8月21日時点での情報
TensorFlowのサイトに、「Neural Machine Translation (seq2seq) Tutorial」(ニューラルネットワークによる機械翻訳(seq2seq)チュートリアル)というページがあります。
参考:https://www.tensorflow.org/tutorials/seq2seq
この最新のチュートリアルでは、ベトナム語を英語に翻訳したり、ドイツ語を英語に翻訳したりします。
そこで、この記事では、チュートリアルに従ってベトナム語を英語に翻訳してみます。
※TensorFlowのseq2seqのチュートリアルとして有名な、英語をフランス語に翻訳するモノは、古いチュートリアル(https://www.tensorflow.org/versions/r1.0/tutorials/seq2seq)ですので、ご注意ください。
この記事では上の黒枠の問題設定でチュートリアルを続けますが、現在(2019/02/14~)のTensorFlowのチュートリアルでは、機械翻訳タスクのリポジトリのコードはいくつか修正されているようです。
参考:https://github.com/tensorflow/nmt
この記事のとおりに実行することもできますが、より最新のドキュメントが読みたい方や、seq2seqの先の技術まで挑戦してみたい方、もっと詳しい説明が読みたい方は、上のURLを参考にしてみてください。
seq2seqの公式チュートリアルに挑戦!
この記事では、チュートリアルの解説は行わず、解説されているプログラムを試す方法を説明します。
なお、プログラムを動作させる環境は、以下の記事でインストールしたTensorFlow 1.5としました。

まだインストールしていない方は、こちらの記事を参考にインストールしてください。
プログラムをダウンロードする
では、チュートリアルのプログラムをダウンロードしましょう。
(1)https://github.com/tensorflow/nmt/にアクセスし、「Clone or download」をクリックして、「Download ZIP」をクリックします。
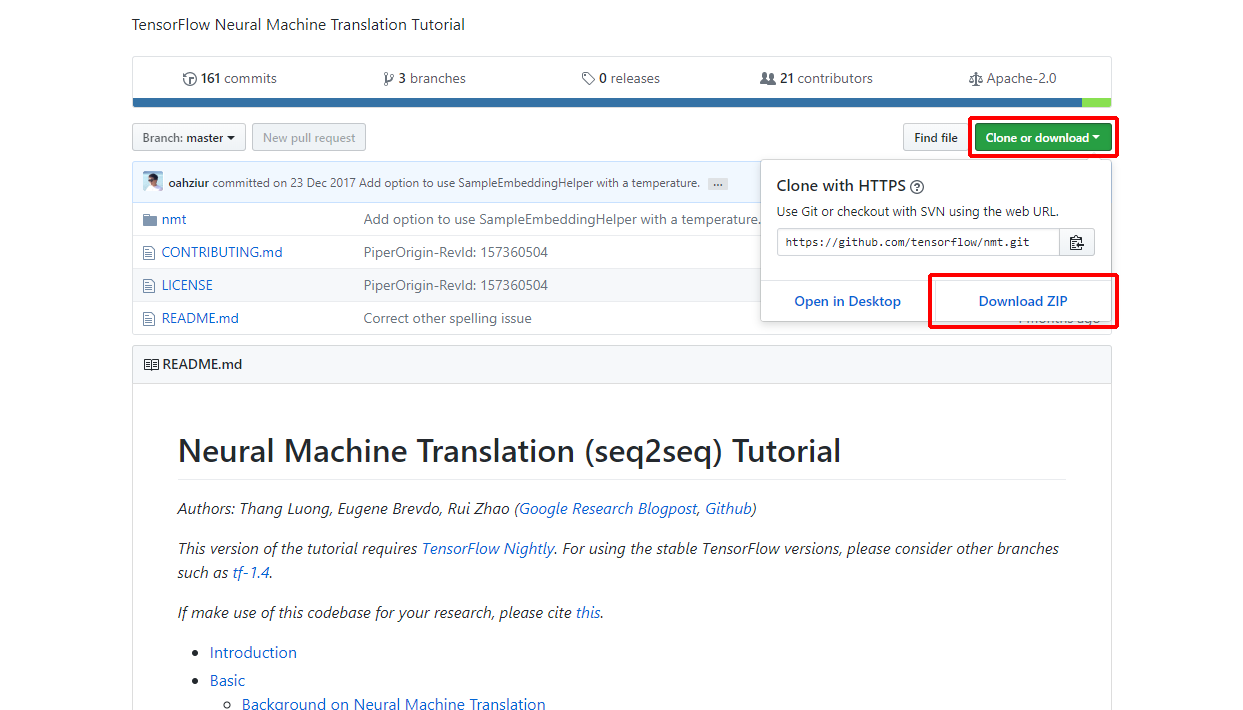
nmt-master.zipがダウンロードされます。
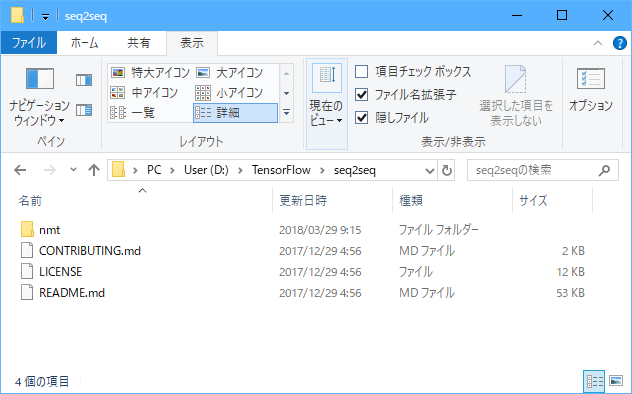
(2)nmt-master.zipを解凍して、任意のフォルダに保存します。
ここでは、「D:\TensorFlow\seq2seq」フォルダに保存しました。
データセットをダウンロードする
次に、データセットをダウンロードします。
チュートリアルのプログラムの中に、ダウンロード用のスクリプトがありますので、以下の手順で操作すれば完了です。
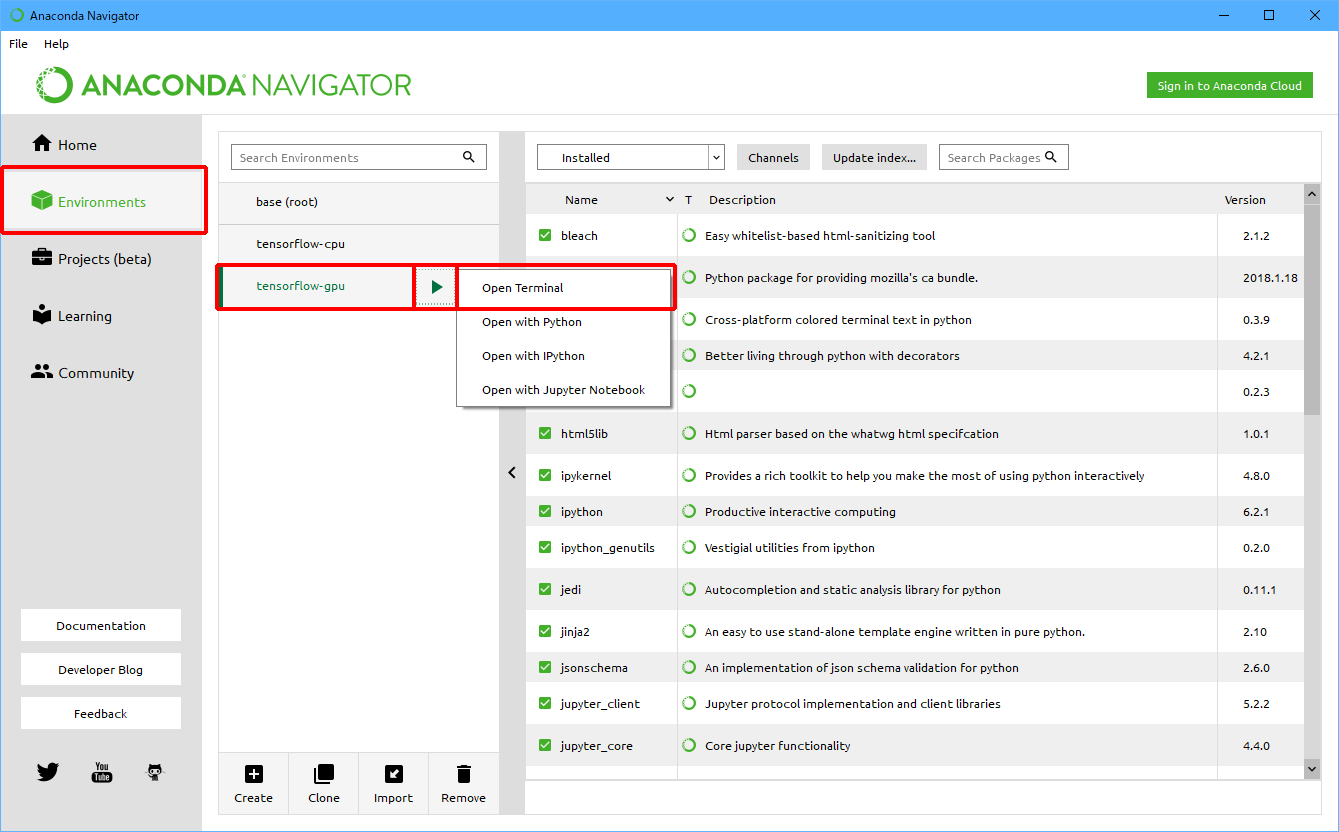
(1)Anaconda Navigatorを起動します。
(2)「Environment」をクリック後、「tensorflow-gpu」をクリックし、「![]() 」をクリックして、「Open Terminal」をクリックします。
」をクリックして、「Open Terminal」をクリックします。
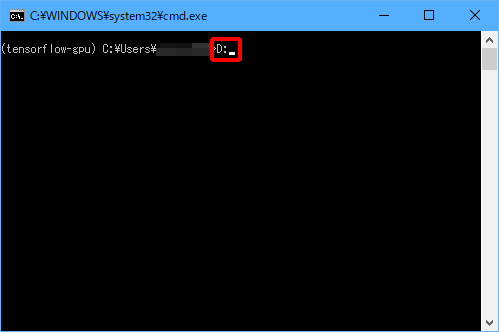
(3)「D:」と入力し、Enterキーを押します。
(4)「cd TensorFlow\seq2seq」と入力し、Enterキーを押します。
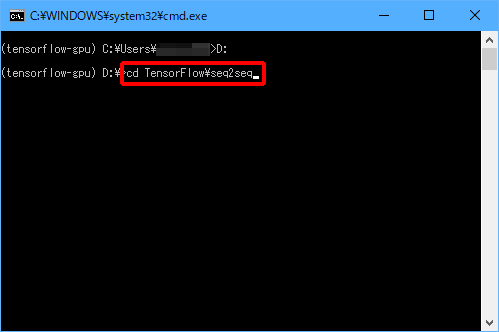
(5)「nmt\scripts\download_iwslt15.sh nmt_data」と入力し、Enterキーを押します。
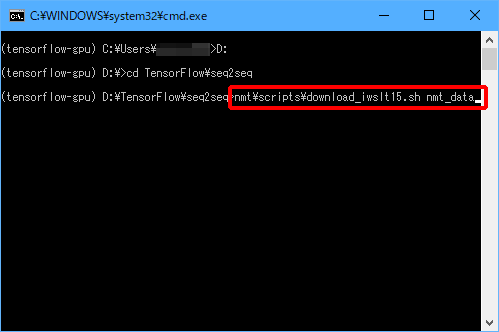
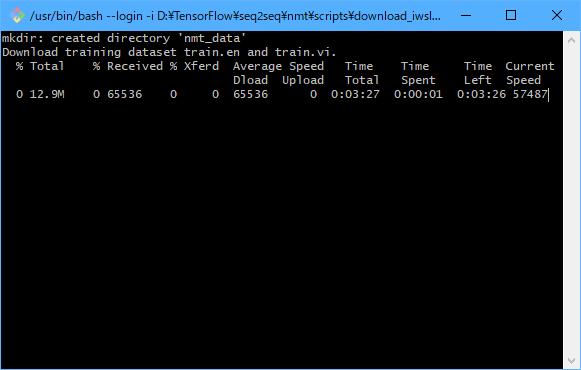
以下のような画面が表示され、ベトナム語データと英語データのダウンロードが始まります。
学習する
ダウンロードしたデータを学習しましょう。
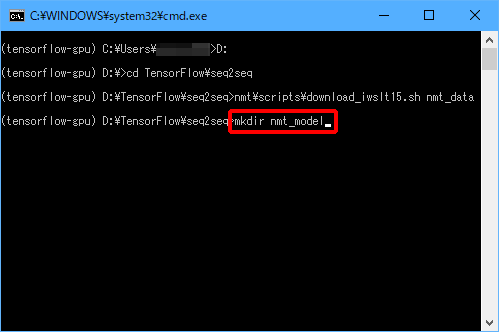
(1)「mkdir nmt_model」と入力し、Enterキーを押します。
(2)「python -m nmt.nmt –src=vi –tgt=en –vocab_prefix=nmt_data/vocab –train_prefix=nmt_data/train –dev_prefix=nmt_data/tst2012 –test_prefix nmt_data/tst2013 –out_dir=nmt_model — num_train_steps=12000 –steps_per_stats=100 –num_layers=2 –num_units=128 –dropout=0.2 –metrics=bleu」と入力し、Enterキーを押します。

学習が始まります。
「step xxx」の部分が、12000になるともうすぐ終了ですので、終了するまで待ちます。
翻訳を試す
ここまでで、何とか学習が終了しました。
次は、学習したモデルを利用して、ベトナム語を翻訳してみましょう。
(1)新しくmy_infer_file.viファイルを作成し、nmt_data/tst2013.viファイルから任意の行をコピーします。
1行に限らず、何行かコピーしても大丈夫です。
今回は以下の1行をコピーしました。
Khi em hát những bài hát từ thời thơ ấu của chúng tôi , cố gắng nhớ những từ mà đến tôi cũng không thể , em ấy gợi nhớ cho tôi một điều rằng : chúng ta biết ít về bộ não đến như thế nào , và cái ta chưa biết phải tuyệt vời đến thế nào .
(2)「python -m nmt.nmt –out_dir=nmt_model –inference_input_file=my_infer_file.vi –inference_output_file=output_infer.en」と入力し、Enterキーを押します。
my_infer_file.viファイルにコピーしたベトナム語が、英語に翻訳され、output_infer.enファイルが作成されます。
(3)output_infer.enをメモ帳で開くと、今回は以下の内容が表示されました。
When you 're going to be a <unk> <unk> of the <unk> and I 'm going to be a <unk> <unk> of the <unk> and <unk> and <unk> and <unk> and <unk> and <unk> and <unk> and <unk> .
<unk>は、学習対象外の語句が入ることを示しているのですが、今回は<unk>ばっかりになってしまいましたね。
また、学習するたびに翻訳結果が変わりますので、ここで説明したとおりにはならなくても操作に誤りがあったわけではありません。
(すでにぱっと見で正しく無さそうですが)ベトナム語はわからないので、Google翻訳で、どちらも日本語に翻訳して、正しく動作しているか評価してみましょう。
元のベトナム語→日本語:
私は子供の頃から歌を歌い、私に来る言葉を覚えようとすると、彼女は私に何かを思い出させます。私たちは、脳がどのように起こったかについてほとんど分かりません。 私たちはどれくらい素晴らしいのか分かりません。
seq2seqが翻訳した英語→日本語:
あなたは<UNK>の<UNK><UNK>ことになるだろうと私は<UNK>と<UNK>と<UNK>と<UNK>の<UNK><UNK>するつもりだときそして<UNK>と<UNK>と<UNK>と<UNK>。
正直、翻訳としてはダメですが、ベトナム語の文章を元に、英語らしき文章が作られているとは言えそうです。
まとめ
今回は、seq2seqの目的を確認してから、ベトナム語と英語のペアを学習し、実際にベトナム語を英語に翻訳してみました。
残念ながら今回の動作結果では、翻訳の内容には問題がありました。
seq2seqを実行するときのパラメーターは自由に変更できますので、仕組みを理解しながら、パラメーターを調節して、よりよい結果が出ないか、挑戦してみてくださいね!




