

AutoEncoder(オートエンコーダ:自己符号化器)をご存知でしょうか?
AutoEncoderは、とても有名なモデルですが、TensorFlowの公式チュートリアルにはありません。
そのため、TensorFlowを使い始めた方は、AutoEncoderをご存知ない方も多いと思います。
今回は、
・AutoEncoderは何がスゴいのか
・AutoEncoderを実際に動かしてみよう
を題材に、手を動かしながらAutoEncoderの理解を深める切っ掛け作りをしてみましょう。
AutoEncoderについての理解が深まってきたでしょうか?「この分野をもっと深く学びたい」と感じた方には、今後のキャリアに大きな影響を与える生成AIのスキルを身につけることが重要です。これからの時代、AIを活用したスキルは時間や収入、キャリアの面で大きなベネフィットをもたらします。
このセミナーでは、実践的なスキルを身につけるための具体的なノウハウを提供します。AIツールの活用法や収益化の流れを学び、独立や副業の道を切り開きませんか?まずはセミナーの詳細を確認して、自分に合った方法を探してみましょう。
AutoEncoderとは
AutoEncoderは、以下の画像のように入力画像(1行目の画像)から復元画像(2行目の画像)を生成するための重み行列を学習するモデルです。
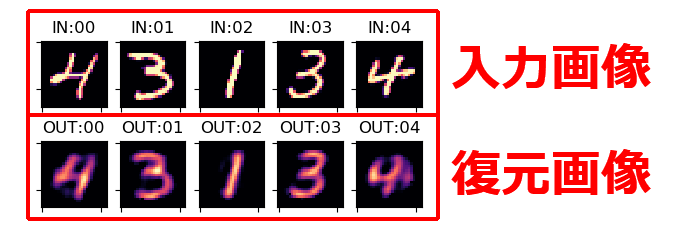
言いかえると、入力画像を圧縮しても(=入力層よりも小さな次元の層を通っても)、入力画像と同一の復元画像を生成できるようなパラメータを求めるのがAutoEncoderです。
元々は、ニューラルネットワークのパラメータを決定するために研究が進められたAutoEncoderでしたが、この目的では使われなくなり、今では画像のノイズ除去(ノイズありの入力画像をAutoEncoderに通して、ノイズ無しの復元画像を生成する)程度でしか使われなくなったようです。
AutoEncoderの作ってみた記事まとめ3選
有用性については、将来に期待するとして、ここからは、簡単なAutoEncoderを作って公開している人たちのプログラムを動かしてみます。
なお、この記事では、以下の記事で紹介した方法で、GPU版TensorFlowをインストールした環境で、AutoEncoderを動作させます。

TensorFlowで機械学習と戯れる: AutoEncoderを作ってみる – Qiita
参考:https://qiita.com/mokemokechicken/items/8216aaad36709b6f0b5c
MNISTデータを圧縮、復元するAutoEncoderを作ってみます。
プログラムの保存と修正
記事に書かれているプログラムを「AutoEncoder.py」として保存します。
TensorFlowのバージョンアップにともない、一部の書きかたを変更する必要があります。
(1)修正前:
# For tensorboard learning monitoring
tf.scalar_summary("l2_loss", loss)
修正後:
# For tensorboard learning monitoring
tf.summary.scalar("l2_loss", loss)
(2)修正前:
# Prepare Session
init = tf.initialize_all_variables()
sess = tf.Session()
sess.run(init)
summary_writer = tf.train.SummaryWriter('summary/l2_loss', graph_def=sess.graph_def)
修正後:
# Prepare Session
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
summary_writer = tf.summary.FileWriter('summary/l2_loss', graph=sess.graph)
(3)修正前:
# Collect Summary summary_op = tf.merge_all_summaries()
修正後:
# Collect Summary summary_op = tf.summary.merge_all()
(4)修正前:
# Draw Input Data(x)
plt.subplot(2*N_ROW, N_COL, 2*row*N_COL+col+1)
plt.title('IN:%02d' % i)
plt.imshow(data.reshape((28, 28)), cmap="magma", clim=(0, 1.0), origin='upper')
plt.tick_params(labelbottom="off")
plt.tick_params(labelleft="off")
# Draw Output Data(y)
plt.subplot(2*N_ROW, N_COL, 2*row*N_COL + N_COL+col+1)
plt.title('OUT:%02d' % i)
y_value = y.eval(session=sess, feed_dict={x: data, keep_prob: 1.0})
plt.imshow(y_value.reshape((28, 28)), cmap="magma", clim=(0, 1.0), origin='upper')
plt.tick_params(labelbottom="off")
plt.tick_params(labelleft="off")
修正後:
# Draw Input Data(x)
plt.subplot(2*N_ROW, N_COL, 2*row*N_COL+col+1)
plt.title('IN:%02d' % i)
plt.imshow(data.reshape((28, 28)), cmap="magma", clim=(0, 1.0), origin='upper')
plt.tick_params(labelbottom=False)
plt.tick_params(labelleft=False)
# Draw Output Data(y)
plt.subplot(2*N_ROW, N_COL, 2*row*N_COL + N_COL+col+1)
plt.title('OUT:%02d' % i)
y_value = y.eval(session=sess, feed_dict={x: data, keep_prob: 1.0})
plt.imshow(y_value.reshape((28, 28)), cmap="magma", clim=(0, 1.0), origin='upper')
plt.tick_params(labelbottom=False)
plt.tick_params(labelleft=False)
必要なライブラリのインストール
Matplotlibをインストールします。
(1)「pip install matplotlib」と入力し、Enterキーを押します。
AutoEncoderの実行
AutoEncoderを実行しましょう。
(1)「python AutoEncoder.py」と入力し、Enterキーを押します。
AutoEncoderの実行が終了すると、以下の画面が表示されます。
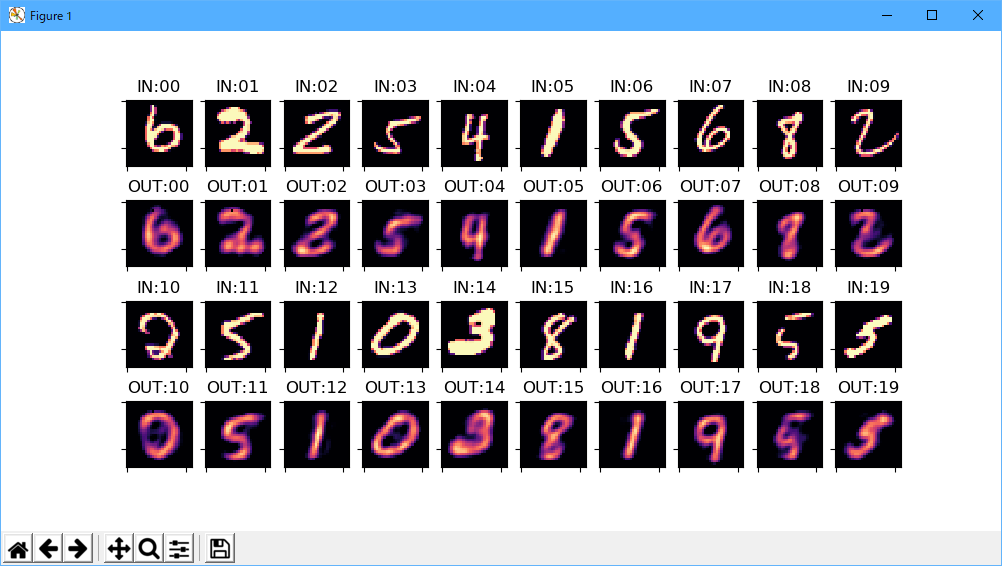
「IN:00」の画像をAutoEncoderを通すと、「OUT:00」の画像が生成されるという表示です。
ちなみに、step数を2000→20000に増やした結果が、以下の画像です。

残念ながらよく言われることですが、step数を増やすだけでは、あまり変化はありませんね。
「H = 50」の数値を変えると、変化がわかりやすいでしょう。
TensorflowでAutoEncoderをやってみた – Qiita
参考:https://qiita.com/onlyzs/items/12c675fb819b8da4ae85
きゅうりの異常検出(anomaly detection)を行うAutoEncoderを作ってみます。
データの準備
GitHubからきゅうりの写真データをダウンロードします。
(1)https://github.com/workpiles/CUCUMBER-9/tree/master/prototype_1にアクセスして、「cucumber-9-python.tar.gz」をダウンロードします。
(2)「cucumber-9-python.tar.gz」を「D:\TensorFlow\AutoEncoder2\prototype_1」フォルダに、解凍します。
プログラムのダウンロード
(1)https://github.com/onlyzs89/autoencoder/tree/masterにアクセスし、「Clone or Download」をクリックして、「Download ZIP」をクリックします。
(2)「autoencoder-master.zip」を「D:\TensorFlow\AutoEncoder2」フォルダに、解凍します。
必要なライブラリのインストール
OpenCV、scipy、scikit-learnをインストールします。
(1)「pip install opencv-python」と入力し、Enterキーを押します。
(2)「pip install scipy」と入力し、Enterキーを押します。
(3)「pip install scikit-learn」と入力し、Enterキーを押します。
AutoEncoderの実行
準備ができたらAutoEncoderを実行します。
(1)「python training.py」と入力し、Enterキーを押します。
AutoEncoderの実行が終了すると、以下の画面が表示されます。
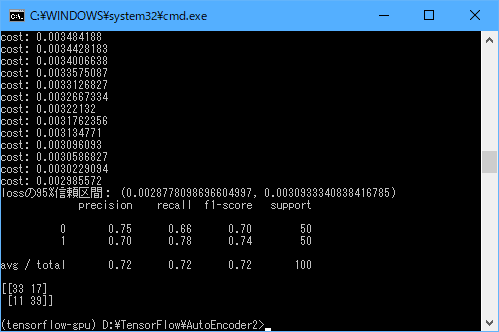
今回の正解率は72%でした。
TensorFlowでAutoencoderを実装してみた – Qiita
参考:https://qiita.com/TomokIshii/items/26b7414bdb3cd3052786
MNISTデータを圧縮、復元するAutoEncoderを作ってみます。
プログラムのダウンロードと修正
https://gist.github.com/tomokishii/7ddde510edb1c4273438ba0663b26fc6にアクセスし、「Download ZIP」をクリックし、ダウンロードしたファイルを「D:\TensorFlow\AutoEncoder3」に解凍します。
この後の手順で「mnist_ae1.py」を実行しますが、TensorFlowのバージョンアップにともない、一部の書きかたを変更する必要があります。
(1)修正前:
# Train init = tf.initialize_all_variables()
修正後:
# Train init = tf.global_variables_initializer()
必要なライブラリのインストール
Matplotlibをインストールします。
(1)「pip install matplotlib」と入力し、Enterキーを押します。
AutoEncoderの実行
MNISTデータを圧縮、復元するAutoEncoderなので、先に説明したモノと同じだろうと思いながら実行してみましょう。
(1)「python mnist_ae1.py」と入力し、Enterキーを押します。
mnist_ae1.pngが生成されます。
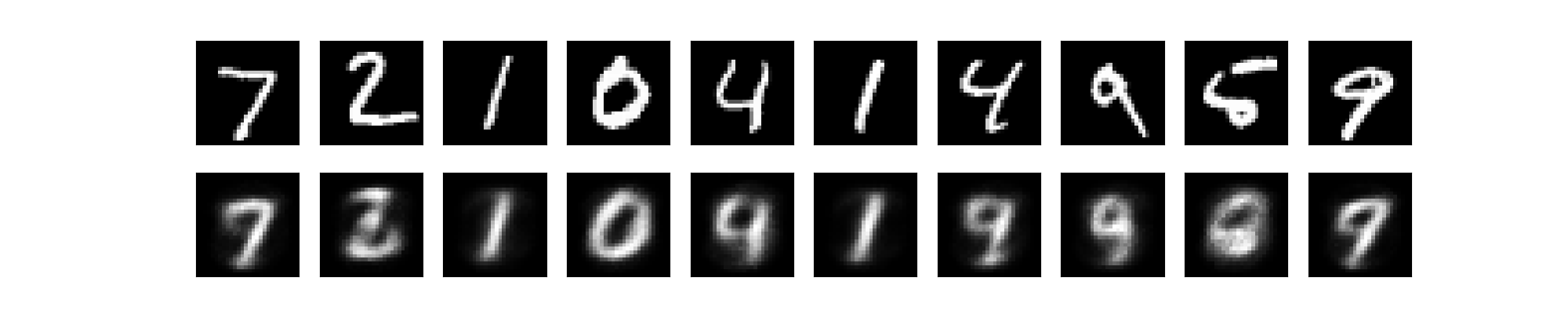
こちらは白黒ですね。
まとめ
今回は、AutoEncoderを3つ実行してみました。
プログラムを読んでみると、1つ目のAutoEncoderでは784次元を50次元に削減、3つ目のAutoEncoderでは784次元を625次元に削減してからの復元でした。
次元数は大きい方が、元の画像を復元しやすいと思うのですが、どちらかというと、次元数が小さい1つ目のAutoEncoderのほうが復元できているような気がします。
ネットワークを比較してみたり、思うがままにパラメータを変えて、どのように復元結果が変わっていくか調べてみたりするのも、とても面白いのでお勧めです。




