

MNISTデータを使って手書き数字を学習したり、RNNにも挑戦したりと、TensorFlowのチュートリアル生活は順調ですか?
今日は、TensorFlowで単語ベクトルを作成するword2vecを試してみます。
単語ベクトルって何?
word2vecって新しいツールをインストールするの?
TensorFlowの記事じゃないの?
と思った方にも、TensorFlowの記事だったのか!と思えるように説明していますので、ぜひ試してみてくださいね。
MNISTデータやRNNに挑戦していない方は、そちらも記事になっていますので、ぜひご覧ください。


TensorFlowのチュートリアルを進める中で、単語ベクトルやword2vecについての理解が深まってきたでしょうか?「もっと効率的に学びたい」「実践的なスキルを身につけたい」と感じた方には、他の環境を活用することもおすすめです。新しい技術を学ぶことは、将来のキャリア形成に大きな影響を与える可能性があります。
特に、AI技術を活用したWeb制作のスキルは、今後の市場での競争力を高めるために非常に重要です。この分野での実践的なノウハウを得ることができる機会を利用すれば、収入源の多様化やキャリアアップを実現することができます。セミナーで詳細を確認し、自分に合った方法を見つけてみませんか?
word2vecとは
word2vecは、元々はGoogleの研究者が開発したツールです。
参考:https://code.google.com/archive/p/word2vec/
現在では、このword2vecツールを元にさまざまな言語で実装されており、word2vecは「単語ベクトルを生成するモデル」を表す単語として有名になっています。
たとえば、gensimというPythonのライブラリに、word2vecの実装(gensim.models.word2vec)があります。
参考:https://radimrehurek.com/gensim/
この記事では、TensorFlowの公式チュートリアルの記事で紹介されているword2vec_basic.py(TensorFlowを使ったword2vecの実装の1つ)を動かしてみます。
word2vecで作成する単語ベクトルとは
ここまで気軽に「単語ベクトル」と書いてきましたが、よく分からないですよね。
少し中学校時代に戻ってみましょう。
数学で習った、座標軸(X軸、Y軸)を覚えているでしょうか。
2つの数値で、平面上の点の位置を表していましたね。
これを、説明の都合上、「平面上のすべての点の位置を表すために用意した、2次元の情報があるベクトル」と呼ぶことにしましょう。
同じような感じで「手元にある文書内の単語の意味を表すために用意した、200~1000次元の情報があるベクトル」が考えられるのではないか、これを単語ベクトルと呼ぼうではないか、というのがword2vecの考え方です。(わかりやすさを優先した解説をしています。厳密ではないので注意。)
もう少し具体的に説明しましょう。
座標軸では、(X座標, Y座標)=(1,2)と書くことで、ある1点の位置を表せました。
(X1, X2, X3, …, X200, …, X1000)=(0.01, 0.99, 0.04, …, 0.54, …, 0.12)と書くことで、ある1つの単語を表せるのではないか、という考え方が単語ベクトルなのです。
人が見てわかりやすいイメージ図が、以下のページで紹介されています。
参考:https://deepage.net/bigdata/machine_learning/2016/09/02/word2vec_power_of_word_vector.html
実際には、このページのように「怠惰さ」とか「スポーツ」とか「土地」といった具体的な言葉で「イチロー」や「プログラマー」を表す数値が決まるわけではありません。
コンピュータだけが分かる「何か」で「イチロー」や「プログラマー」を表す数値(=単語ベクトル)が決められます。
word2vecの革新的なところは、プログラムが多くの文章を読み取ることで、ここで書いた「プログラムだけが分かる「何か」」とか「表す数値(=単語ベクトル)」を、プログラムがそれらしく決められるというところなのです。
具体的にどのように単語ベクトルを計算するのか、とか、単語ごとに単語ベクトルが決められるとどんな計算ができるのか、といったことは上記のページでも紹介されていますので、ここまで読んだところで、戻ってみても良いでしょう。
日本語の単語ベクトルを作成するには
実は、公開されているword2vecのプログラムは、基本的には英語の文章を読んで英語の単語ベクトルを作成するコードになっていることがほとんどです。
そのため、そのままでは日本語の単語ベクトルを作成できません。
ただ、プログラムの動作さえ分かってしまえば、ただ1点を除いて、英語と日本語を置き換えることは難しくありません。
「ただ1点を除いて」と書いたのは、英語でも日本語でも、word2vecを利用するには、単語ごとに区切る必要があるためです。
英語の場合は、基本的には半角スペースなどの記号で区切れば、単語ごとに区切れそうですね。
一方、日本語は、単語ごとに区切ることが難しい言語です。
あえて難しい例をあげると、「すもももももももものうち」です。
漢字を混ぜると「李(すもも)も桃も桃のうち」、単語ごとに-(ハイフン)で区切ると「すもも-も-もも-も-もも-の-うち」ですね。
word2vecで日本語の単語ベクトルを作成するには、このように文章をうまく単語ごとに区切るプログラムが必要なのです。
このように単語を区切る作業は、「分かち書き」と呼ばれます。
同じような作業で「形態素解析」という作業もあります。
「形態素解析」は、「分かち書き」に加えて「品詞判別など」を行う作業です。
まとめると、日本語の単語ベクトルを作成するには、「分かち書き」または「形態素解析」を行えるプログラムが必要なのです。
「分かち書き」さえできれば、英語用のword2vecに日本語の単語をあてはめるようにプログラムを修正して、見事に日本語の単語ベクトルを計算できるでしょう。
日本語の「分かち書き」または「形態素解析」を行えるプログラム
有名なところでは、MeCab、ChaSen、JUMANです。
TensorFlowと組み合わせる場合は、TensorFlowと同じようにお手軽にPythonで使えるMeCabが良いでしょう。
word2vecの公式チュートリアルに挑戦!
ここからは、公式チュートリアル「Vector Representations of Words」に挑戦してみましょう。
参考:https://www.tensorflow.org/tutorials/word2vec
この記事では、コードの解説は上のページにお任せして、解説されているプログラムを試してみることにします。
プログラムをダウンロードする
以下のページから、word2vec_basic.pyをダウンロードします。
任意のフォルダに保存すればよいので、ここでは「D:\TensorFlow\word2vec」フォルダに保存します。
単語ベクトルを作成する
word2vec_basic.pyで単語ベクトルを作成するために必要なデータ(以下のtext8.zip)は、word2vec_basic.pyを実行すると、自動的にダウンロードされます。
参考:http://mattmahoney.net/dc/text8.zip
したがって、単純にword2vec_basic.pyを実行すれば良いことになるのですが、Windowsの場合はそうは行きませんでした。
ちょっと説明しておきましょう。
word2vec_basic.pyを修正する
Windowsの場合は、word2vec_basic.pyを少し修正する必要がありました。
最後の方に以下の記載があります。
plot_with_labels(low_dim_embs, labels, os.path.join(gettempdir(), 'tsne.png'))
これを、以下のように修正してください。
plot_with_labels(low_dim_embs, labels, 'tsne.png')
これで準備完了です。
word2vec_basic.pyを実行する
プログラムとデータの準備ができたところで、TensorFlowをインストールした環境で機械学習を実行してみましょう。
実行後に画像を生成するために、いくつかパッケージをインストールする必要がありました。
ここでは、Anaconda NavigatorからGPU版TensorFlowをインストールしたPython環境を起動して、必要なパッケージのインストールした後で、「D:\TensorFlow\word2vec」フォルダに保存したword2vec_basic.pyを実行する操作を説明します。
(1)Anaconda Navigatorを起動します。
(2)「Environment」をクリック後、「tensorflow-gpu」をクリックし、「![]() 」をクリックして、「Open Terminal」をクリックします。
」をクリックして、「Open Terminal」をクリックします。
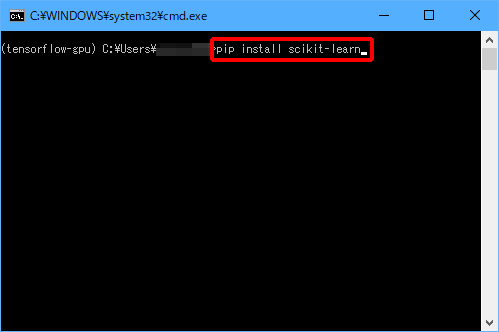
まずは、パッケージをインストールしましょう。
(3)「pip install scikit-learn」と入力し、Enterキーを押します。
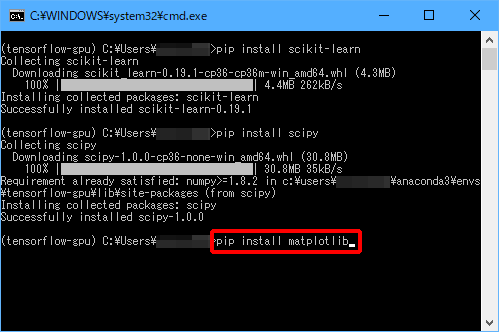
(4)「pip install scipy」と入力し、Enterキーを押します。

(5)「pip install matplotlib」と入力し、Enterキーを押します。
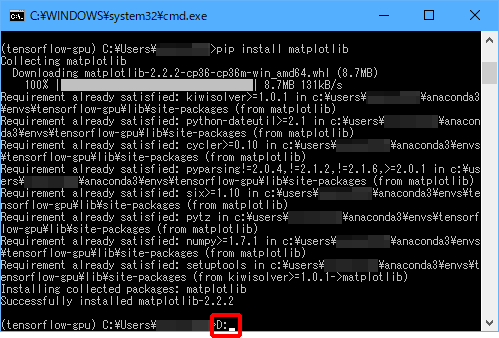
パッケージがインストールできたら(または、すでにインストール済みであったら)word2vec_basic.pyを実行しましょう。
(6)「D:」と入力し、Enterキーを押します。
(7)「cd TensorFlow\word2vec」と入力し、Enterキーを押します。
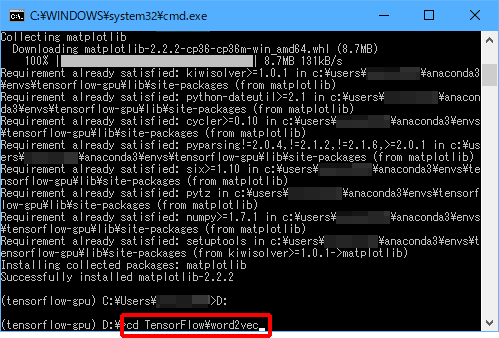
(8)「python word2vec_basic.py」と入力し、Enterキーを押します。
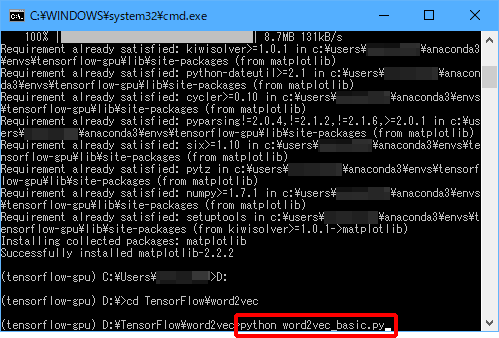
実行中は以下のような画面が表示されます。
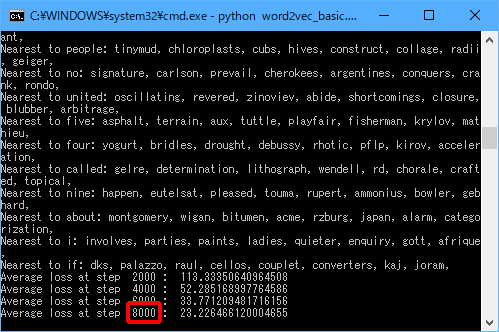
「8000」の部分が100000になると終了ですので、終了するまで待ちます。
終了すると、以下のように表示されます。
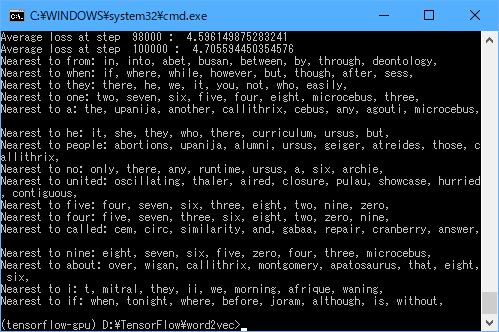
今回は「Nearest to nine」(nineに近い単語)として、「eight」、「seven」、「six」、「five」、…と数字が列挙されていますね。
実行結果の確認
上で説明したword2vec_basic.pyの修正をした場合は、word2vec_basic.pyと同じフォルダに「tsne.png」が作成されます。
修正しなかった場合は、OSの作業用ディレクトリに「tsne.png」が作成されているはずですので、探してみてください。
こちらでは、以下のような画像作成されました!
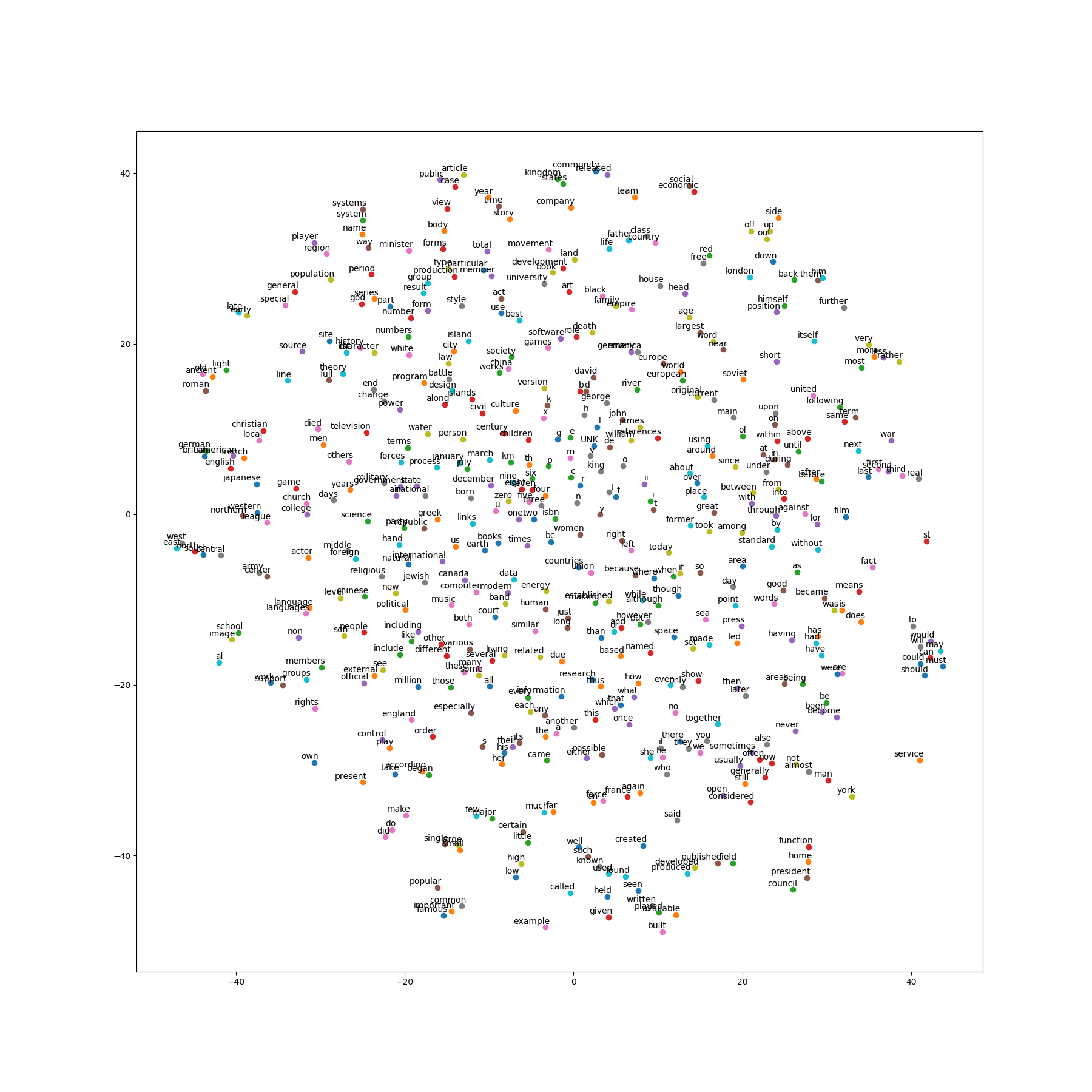
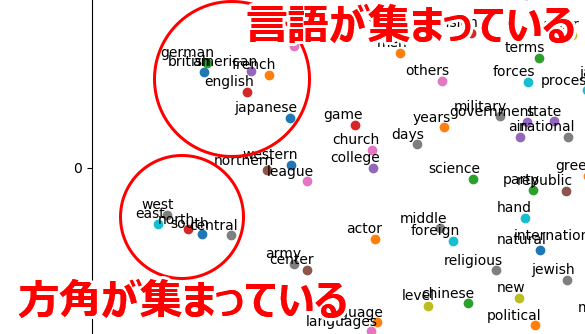
一部を拡大して見ると、(どこか)似通った単語が集まっている箇所もありますね。

まとめ
今回は、(TensorFlowによらない)word2vecを紹介しました。
また、TensorFlowの公式チュートリアルの記事から、word2vecで単語ベクトルを作成するプログラムであるword2vec_basic.pyを動かしてみました。
このプログラムになれたら、公式チュートリアルの記事のおすすめのとおり、word2vec.pyにも挑戦してみてくださいね!




