

みなさんはpandasを使っていますか?pandasは今やデータを扱うためのライブラリとして、スタンダードに使われています。
この記事では、pandasの使い方について
- pandasとは
- csvファイルを読み込む
- データの内容を確かめる方法
- リストから新しいカラムを追加する方法
- データに変更を加える方法
といった基本的な内容から、一歩進んだ内容についても解説していきます。pandasの基礎について、しっかりと学習していきましょう。
なお、Pythonの記事については、こちらにまとめています。
pandasとは
pandasはPythonのライブラリの1つでデータを効率的に扱うために開発されたものです。例えばcsvファイルなどの基本的なデータファイルを読み込み、追加や、修正、削除、など様々な処理をすることができます。1次元のデータを扱うSeriesや2次元のデータを扱うDataframeといった主要なデータ構造を備えています。
非常に簡潔にデータを扱えて、使い勝手がとても良いので、多くのデータサイエンティストに愛用されています。
pandasの基本的な使い方
それでは早速pandasを使ってみましょう。
read_csvの使い方
それでは、さっそくpandasを使用してみましょう。今回はtest.csvと名前の付いたファイルを扱っていきます。
[test.csv]
,山田拓朗,23 2,根岸広海,28 3,広瀬響,88 4,中曽根庄司,102 5,中山裕子,3 6,滝本彩乃,43 7,遠藤翔子,62 8,新見真司,98 9,大内雅,12
pandasでcsvファイルを読み込むにはread_csvメソッドを使用します。
import pandas as pd
data = pd.read_csv("test.csv",index_col=0)
data
実行結果

read_csvメソッドのindex_colという引数はindexをどのカラムにするのか指定します。test.csvのindexカラムは1番始めにあるので、「0」を指定しました。もしも、index_colをを指定しない場合はpandasによって自動的にindexが追加されるので、注意が必要です。(場合によってはindexが2つになってしまいます。)
データの内容を確かめるメソッド
それでは先ほど読み込んだデータの内容を確かめていきましょう。データがどんなカラムを持つのか確かめるためにはcolumnsメソッドを使います。また、indexの詳細を確かめるにはindexメソッドを使います。
data.index data.columns
実行結果
Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8], dtype='int64', name='index') Index(['name ', 'age'], dtype='object')
このように、Indexでは、dype(data type)として「int64」、そしてnameにはindexが返ってきます。
一方、columsではカラムの名前、そしてdtype(data type)として「object」が返ってきます。
その他columsやindexメソッド以外にpandasには
- データの列と行の数を返すshapeメソッド
- データの要約統計を出力するdescribeメソッド
- データの詳細を出力するinfoメソッド
- データの始めからいくつか出力するheadメソッド
- データの終わりからいくつか出力するtailメソッド
などがあります。実際に使用してみましょう。
shapeメソッド
data.shape
(9, 2)
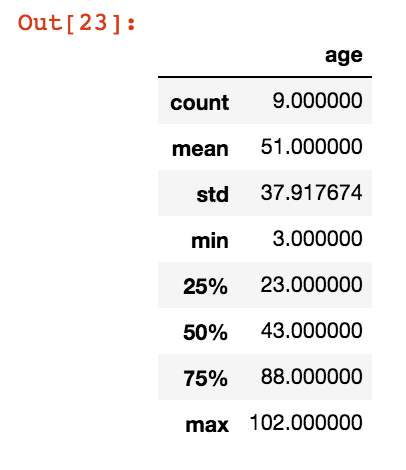
describeメソッド
data.describe()
実行結果
infoメソッド
data.info()
実行結果
<class 'pandas.core.frame.DataFrame'> Int64Index: 9 entries, 0 to 8 Data columns (total 2 columns): name 9 non-null object age 9 non-null int64 dtypes: int64(1), object(1) memory usage: 216.0+ bytes
headメソッド
data.head(3)
実行結果

tailメソッド
data.tail(3)
実行結果

これらのメソッドを使いこなせば、簡単にデータの内容を確かめることができます。たくさんあるように感じますが、それぞれ挙動が異なりますので、しっかりと覚えるようにしましょう。
リストから新しいカラムを追加する方法
Pythonのリストから新しいカラムを追加するには、リストを一度pandasで扱えるSeries型に変換する必要があります。Series型はindexとたった1つのカラムを持つデータのことです。それでは今回はheigth(身長)のカラムを追加していきましょう。
import numpy as np list = np.random.randint(140,200,9) #カラムに追加したいリスト add_list = pd.Series(list) #ここでリストをSeriesオブジェクトに変換 data["height"] = add_list.values #valuesをつけることで追加可能な形に変換 data
実行結果
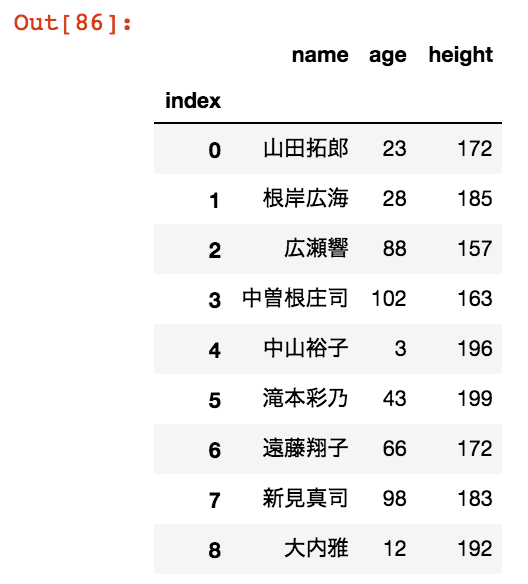
このように、新しいheightのカラムを簡単に追加できました。また、今回heightのカラムの数値はnumpyを使って、ランダムに生成したものを使っています。numpyを使えばランダムな配列を高速かつ簡単に作成できて便利です。
詳しくはこちらの記事をご覧ください。
データに変更を加える方法
カラム全体に変更を加えたいときにはapplyメソッドを使えば、簡単に実現できます。今回はageのカラムの数値を半分にしてみましょう。
data['age'] = data.apply(lambda x:x['age']//2,axis=1) data
実行結果
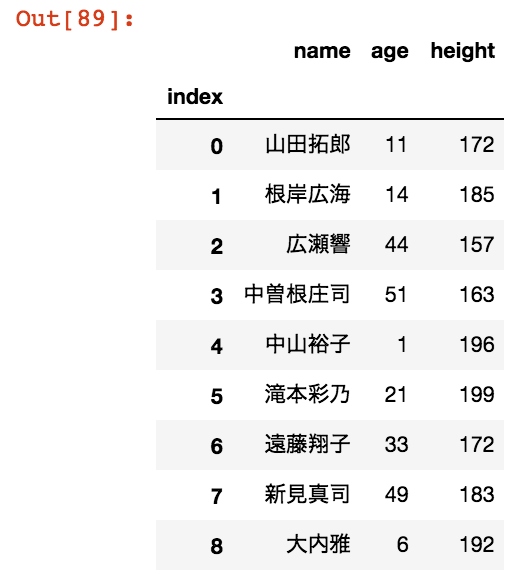
このように、applyはlambda式を使ってカラムの値に変更を加えます。今回は半分にするために演算子「//」を使用しました。こちらの演算子はpython3で使用可能で、少数点以下を切り捨てます。lambda式の使い方はこちらの記事で紹介していますので、一読することをおすすめします。

まとめ
いかがでしたでしょうか?
この記事では、pandasの使い方を解説しました。データを扱う際にpandasが使えるととても便利ですね。今回紹介しきれなかったもので便利なメソッドがまだまだ数多くありますので、これを機にpandasについてもっと勉強してみましょう。
もしpandasの使い方について忘れてしまったらこの記事を確認してくださいね!




