


データ分析の手法の一つである「機械学習」とは、データをもとに機械が自動で学習を行い、データの背景にあるルールやパターンを発見するものです。近年では、AI分野が急激な成長を遂げたことで、機械学習も多くの注目を集めています。
しかし、AIやIoTに比べ、機械学習に対する一般的な認知度は低いのが現状です。実際、機械学習について明確なイメージを抱けていない人も多いのではないでしょうか。
そこで、今回は機械学習を用いたデータ分析の方法を、具体的な手法も交えわかりやすく解説します。機械学習を用いたデータ分析の学習法も紹介するので、ぜひ参考にしてください。
この記事の監修者

フルスタックエンジニア
音楽大学卒業後、15年間中高一貫進学校の音楽教師として勤務。40才のときからIT、WEB系の企業に勤務。livedoor(スーパーバイザー)、楽天株式会社(ディレクター)、アスキーソリューションズ(PM)などを経験。50歳の時より、専門学校でWEB・デザイン系の学科長として勤務の傍ら、副業としてフリーランス活動を開始。 2016年、株式会社SAMURAIのインストラクターを始め、その後フリーランスコースを創設。現在までに100名以上の指導を行い、未経験から活躍できるエンジニアを輩出している。また、フリーランスのノウハウを伝えるセミナーにも多数、登壇している。
本記事の解説内容に関する補足事項
本記事はプログラミングやWebデザインなど、100種類以上の教材を制作・提供する「侍テラコヤ」、4万5,000名以上の累計指導実績を持つプログラミングスクール「侍エンジニア」を運営する株式会社SAMURAIが制作しています。
また、当メディア「侍エンジニアブログ」を運営する株式会社SAMURAIは「DX認定取得事業者」に、提供コースは「教育訓練給付制度の指定講座」に選定されており、プログラミングを中心としたITに関する正確な情報提供に努めております。
参考:SAMURAIが「DX認定取得事業者」に選定されました
記事制作の詳しい流れは「SAMURAI ENGINEER Blogのコンテンツ制作フロー」をご確認ください。
機械学習を用いたデータ分析とは?

機械学習はAIやIoTと同様に、幅広い分野からの需要が高まっています。そんな機械学習を用いたデータ分析とは、一体どのような手法を指すのでしょうか。
こちらでは、以下の観点から機械学習を用いたデータ分析について紹介していきます。
機械学習とデータ分析の違い
機械学習とは、データ分析の方法の一つで、与えられたデータをもとにコンピューターが自動的に「学習」を行うプロセスです。数値や画像などの大量のデータを解析し、そのデータに含まれたパターンや関連性を見つけることに特化しています。
活用例として、顔認証システムやスパムメールの識別などが挙げられます。特に近年では、学習結果に基づいて「予測・判断」する機能が重視されています。
一方データ分析とは、収集した情報の整理・加工・取捨選択を経て分析する一連のプロセスのことです。この手法の一つに、機械学習が含まれます。
データ分析を行うことで、数値にもとづく合理的な意思決定が可能となり、課題の発見やビジネスチャンスに繋げることができます。
なお、データ分析と機械学習の概要をそれぞれ詳しく知りたい人は次の記事を参考にしてください。
→ データ分析とは?活用例や手法、必要なスキルもわかりやすく解説
→ 機械学習とは?できることや事例を初心者向けにわかりやすく解説
統計学との違い
統計学は、経験的に得られたデータから、その規則性・不規則性を明らかにする学問です。膨大なデータを分析し、データの特徴や規則性・不規則性、データ同士の関連性を割り出すことで、未来の結果を推測します。
機械学習やデータ分析と似ているようにも感じられますが、この2つは「データサイエンス」という領域に分類され、データを使って有益な知見を引き出すことを目的とするため、推測に対する説明を目的とする統計学とは異なります。
機械学習では、将来の予測の精度を追求し、統計学は、確実性のあるアクションを打ち出す際に用いられることが多いです。
機械学習の種類

機械学習には様々な手法があります。主な機械学習の手法は以下の通りです。
それぞれの手法について詳しく解説していきます。
教師あり学習
機械学習の手法の一つである「教師あり学習」は、その名の通り、教師となるデータをもとにモデルを学習させる手法です。既知の入力データとそれに対応する出力データを使用してモデルを訓練していきます。
教師あり学習は、新しい入力データを学習させ、精度の高い出力・予測を行えるようにモデルを最適化することを目的に実施します。正解データを大量に学習していくことで、新しいデータにも対応できるようになるのです。
教師あり学習の代表的な応用例の一つが、需要予測システムです。需要予測システムでは、蓄積されたデータの分析を行うことで、在庫の最適化や収益の最大化などを実現します。
ただし、高い精度で需要を予測するには、過去の実績や天候による影響などの要素を学習する必要があります。教師あり学習によるシステムの精度を高めるには、定期的なデータ検証・改善の作業も重要です。
教師なし学習
機械学習の学習手法の一つである「教師なし学習」は、モデルに対し、学習データに正解を与えない状態で学習させる学習手法のことを指します。教師なし学習を実施する目的は、モデルがデータの背景に潜む隠れた構造やパターンを自動的に発見することです。
教師なし学習は、教師あり学習のように、特定の答えに到達することが目的ではありません。教師なし学習では、特定のデータの関連性や類似性が求められます。
教師なし学習の具体例の一つが、自動運転AIの画像認識です。こちらはまだ開発段階の技術ではありますが、教師あり学習の弱点を補うために教師なし学習が用いられたとされています。
教師あり学習を自動運転技術に用いる場合、モデルに十分なデータを学習させるために、膨大な時間と作業を要します。一方、教師なし学習の場合は、正解・不正解のデータを用意する必要がないため、作業負担を大幅に軽減することが可能です。
このような側面からも、教師なし学習は注目を集めており、今後AIや機械学習の分野でさらに活躍すると予想されています。
半教師あり学習
「半教師あり学習」は、教師あり学習と教師なし学習の中間的な学習手法です。半教師あり学習では、ラベルのついていないデータと、ラベルのついているデータを同時に学習していきます。
少量のラベル付きデータを利用して、大量のラベルなしデータを学習するので、データ量が多く、ラベル付けが困難なデータをモデルに学習させる際に用いられることが多い手法です。また、教師あり学習と教師なし学習の両方を組み合わせることで、より高い予測精度を期待することができます。
半教師あり学習は、自然言語処理の分野で活用されることが多いです。
一部のデータをラベリングすることで、膨大な未ラベルのデータを分類することができるという特徴が重宝されています。ほかにも、画像認識や異常察知のシステム開発でも、半教師あり学習が用いられています。
強化学習
「強化学習」は、AIやコンピューターなどの「エージェント(学習者)」にデータを与えて学習させる機械学習の手法の一つです。エージェントは与えられたデータを手掛かりに試行錯誤して学び、データの価値を最大化することを目指します。
エージェントが自ら行動を選択し、その結果によって次の行動を決定するという点が、機械学習最大の特徴であるといえるでしょう。
例えば、ロボットの性能の向上などに強化学習が用いられます。初歩的な内容から学習していき、徐々にアルゴリズムを調整していくことで性能を高めます。
強化学習を行うことで、教師あり・なし学習では解決しにくい問題にも、新たなアプローチでの解決を目指すことが可能です。
機械学習を用いたデータ分析の手法5選

機械学習を用いたデータ分析の手法を5つ紹介します。
それぞれの特徴を詳しく解説していきます。
主成分分析
主成分分析は、高次元の特徴量を圧縮し、二次元や三次元空間にマッピング(射影)する機械学習の手法です。主成分分析を行うことで、多次元データをより少ない次元で表現することができます。
元のデータが持つ情報を損なわないように「主成分」と呼ばれる情報を生成し、データの本質的な特徴や構造を維持しながら、計算時間やリソースの大幅な節約も実現できる手法です。主成分分析は多数の変数を持つデータセットに対して有効で、複雑なデータ分析も簡略化できます。
また、データの次元数が3次元以下となった場合には、データを視覚的に表現するグラフを作成することもできるため、複数人との情報の共有にも適しています。
ナイーブベイズ
ナイーブベイズは、分類問題の解決に有効な手法です。具体的には、ベイズの定理に基づき、データが特定のカテゴリに属する確率を計算を行う分析方法です。
計算量が少なく処理が高速なので、大規模なデータの処理にも適しており、一方でシンプルな問題の解決にも活用することができます。
ナイーブベイズでは、「文章全体が出現する確率」と「特定の単語が文章内で出現する確率」の二つの確率を用います。これらの情報をベイズの定理に基づき計算し、確率が最も高くなるカテゴリにデータを分類するという仕組みです。
ナイーブベイズは主にスパムメールの識別やテキストの自動分類などに活用されています。
Recurrent Neural Network
Recurrent Neural Networkとは、時系列データやシーケンシャルデータを用いた予測を行うニュートラルネットワークのモデルの一種です。
Recurrent Neural Networkは、過去の情報を利用して現在および将来の入力に対するネットワークの性能を向上させることを目的としています。ネットワークにループ構造を用いることで、過去の情報を隠れた状態で保存し、シーケンスで処理します。
また、可変長の入力を扱うことができるという特徴は、時系列データの解析や自然言語処理の分野に有効で、現在も該当分野では活用されることが多いようです。
Feed Forward Neural Network
Feed Forward Neural Networkは、ニューラルネットワークの中でも最も単純なモデルの一つです。データの流れが一方向で、ループや交差が起きない点が特徴です。
Feed Forward Neural Networkは三層構成で、入力されたデータをそのまま出力する「入力層」、入力されたデータに対して何らかの変換を行い出力する「中間層」、中間層の値を受け取って何らかの変換を行い値を出力する「出力層」に分類されます。
入力層に入力したデータは、順に中間層に伝播し、最後に出力層に値を伝播して値を導出します。
Feed Forward Neural Networkは、顔認証システムや自動運転、自動翻訳など、幅広く活用されているシステムです。
Generative Adversarial Networks
Generative Adversarial Networksは、生成モデルの一種です。用意されたデータから特徴を学習し新たに擬似的なデータの生成を行うものを指します。
訓練データをもとに偽のデータを生成することが得意です。
このような、疑似的なデータを作り出すことを「生成」と言い、それを実現するモデルのことを「生成モデル」と呼びます。
Generative Adversarial Networksを活用することで、低画質の画像を高画質に出力したり、テキストの情報をもとに新たな画像を生成することができます。
機械学習を用いたデータ分析の学習方法

機械学習を用いたデータ分析は、現在も多くの分野からのニーズがあり、今後も需要が高まることが予想されます。IT人材としての市場価値を高めるために、学習を始めたいと考える方も多いはずです。
こちらでは、機械学習を用いたデータ分析の学習方法を解説します。機械学習やデータ分析に関する学習を始めようと考えている方は、ぜひ参考にしてください。
独学で学ぶ
機械学習やデータ分析に関する内容は、書籍やインターネットの情報をもとに独学でも学ぶことができます。
| 独学で学ぶメリット | ・自分の好きなタイミングで学習を進められる ・データ分析を体系的に学べる ・学習コストを抑えられる |
| 独学で学ぶデメリット | ・参考書を選ぶ手間がかかる ・モチベーションの維持が難しい ・不明点を解決しづらい |
書籍やインターネットを用いての学習においては、機械学習やデータ分析を体系的に学ぶことができるというメリットがあります。また、学習の開始にあたって、多額のコストが発生することはほとんどありません。
場所や時間の制限を受けない点も長所のひとつでしょう。
一方、独学の場合は、参考書などを自分で選択しなければなりません。また、学習に対するモチベーションの維持も負担に感じる場合があるでしょう。
さらに、分からない点を即座に解決しにくい部分もデメリットであると考えられます。
長所と短所の両方を鑑みつつ、自分に合った学習方法を模索していくことをおすすめします。
なお、次の記事では機械学習を始めるためのロードマップについて詳しく解説しているので、あわせて参考にしてください。

スクールに通う
機械学習やデータ分析に関する内容は、専門のスクールや講座を受講することで学ぶこともできます。
| スクールに通うメリット | ・効率的に学習を進められる ・実践的な講義を受講することができる ・疑問点を現役のプログラマーに質問できる |
| スクールに通うデメリット | ・初期費用やランニングコストがかかる ・場所や時間の指定がある |
機械学習やデータ分析が学べるスクールは独学に比べ費用がかかるものの、現役エンジニア指導のもと、効率的に知識やスキルを身につけるためのカリキュラムが設定されています。
そのため、初心者の方でも着実にスキルを養うことができます。
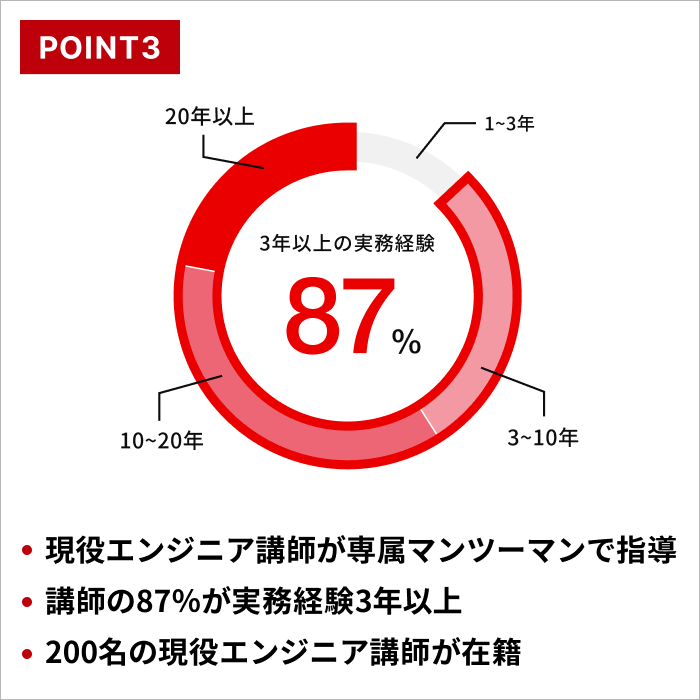
なお、機械学習やデータ分析が学べるスクールのなかでも、機械学習エンジニアやデータサイエンティストへの転職を見据えて学習したい人には「侍エンジニア」がおすすめです。






| 分割料金 | 一括料金 | 受講期間 |
|---|---|---|
| 4,098円~ | 16万5,000円~ | 1ヶ月~ |
- 累計指導実績4万5,000名以上
- 大学生は学割料金(10%OFF)で受講可能
- 受講生の学習完了率98%
受講料の最大70%が給付される侍エンジニアの「データサイエンスコース」「AIアプリコース」では、金銭面での支援を受けつつ機械学習のスキル習得から転職活動・就業後のフォローアップ(※1)までを一貫してサポートしてもらえます。
※1:転職後の1年間、転職先での継続的な就業や転職に伴う賃金上昇などのフォローアップ
学習と金銭面をどちらもサポートしてくれる侍エンジニアなら、未経験からでも安心して機械学習のスキルを習得できますよ。
公式サイトで詳細を見るまとめ
今回は、機械学習を用いたデータ分析の概要や、具体的な手法、それらの学習方法について解説しました。
AIやIoTの発展とともに、機械学習やデータ分析の需要が高まっています。今後も様々な分野から注目を集め、広く活用されるでしょう。
機械学習やデータ分析のスキルを身につけて市場価値の高い人材になるには、専門性の高い学習を実践することが重要です。機械学習やデータ分析に関する学習を開始したいとお考えの方は、ぜひスクールの利用をご検討ください。




