

この記事では、ビジネスの現場でも使われるデータ解析手法「ロジスティック回帰」を紹介します!
この記事ではsciki-learnを使って最短経路でロジスティック回帰を試す方法をハンズオンで学んでいきたいと思います。
この記事でわかること
- ロジスティック回帰とは?
- ロジスティック回帰のscikit-learn実装の試し方
- 更に詳しく学ぶ方法
名前は聞いたことがあるけど試したことはない、そんな方はこの記事で一緒にロジスティック回帰について学んでいきましょう。
この記事のコードは、MacにてPython 3.7, scikit-learn 0.19で動作確認しました。
ロジスティック回帰についての理解が深まりましたか?「自分一人での習得は難しそう…」と感じた方もいるかもしれませんが、別の環境を活用することで、より実践的なスキルを身につけることができます。特に、AIとWeb制作を組み合わせたスキルを学ぶことで、未来の収入やキャリアの選択肢が広がります。
このようなスキルを実際に活用し、収益化につなげるための具体的なノウハウを提供する機会があります。興味を持たれた方は、まずはセミナーの詳細を確認して、自分に合った学びの方法を見つけてみませんか?
ロジスティック回帰とは
ロジスティック回帰とは、例えば「その人の購入履歴」から、「この人が次にこの商品を買うかどうか」のような2値の予測を行うアルゴリズムです。
ちなみに、このような予測したい変数のことを「目的変数」と呼びます。
目的変数と説明変数(目的変数を説明する変数)についてはこの記事を参考にしてください。
そのような「未来のデータを予測するアルゴリズム」のことを「回帰」と言ったりします。
そのあたりの基礎から解説を丁寧にしてくださっているスライドを拝見しましたので、おすすめします。
ロジスティック回帰では予測モデルをシグモイド関数(ここではロジスティック関数と呼びます)で作成します。
シグモイド関数(ロジスティック関数)は以下のような形になっています。
# ライブラリのimport
import numpy as np
import matplotlib.pyplot as plt
# ロジスティック関数
def logistic_function(x):
return 1/ (1+ np.exp(-x))
# プロットの作成
x = np.linspace(-10,10,1000)
plt.plot(x, logistic_function(x))
plt.title("logistic function")
plt.xlabel("x")
plt.ylabel("y")
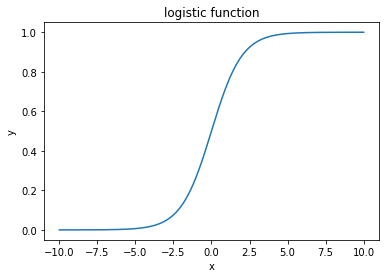
このシグモイドの値が出力になるわけですが、実際にはこのlogisitic_functionの引数xに、説明変数と係数、バイアスなどを使った1次関数を渡します。
ここでは簡単に試すのが目的なので、そのあたりついては解説をしませんが、また別の記事で書きたいと思います。
scikit-learnで試す
ではロジスティック回帰をscikit-learnで試してみましょう。
二つのクラスを持つデータセットを使って、教師データで学習してテストデータの(クラス)ラベルを予測する問題を行います。
ライブラリのimport
上でimportしたライブラリに追加して、以下のものをimportします。
# 上でimportしたもの import numpy as np import matplotlib.pyplot as plt # 追加でimportするもの import pandas as pd from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression as LR
importの内訳は以下の通り。
- Numpy
- 行列計算
- matplotlib
- プロット
- pandas
- データの読み込みや整形、それと可視化
- sklearn.datasets
- 今回使うデータのダウンロード
- sklearn.model_selection.train_test_split
- 教師データとテストデータの分割
- sklearn.linear_model.LogisticRegression
- ロジスティック回帰の入っているモジュール
- LogisticRegressionは長いので、LRとあだ名をつけました。
データの読み込み
ロジスティック回帰を試すための学習・テストに使うデータを読み込みましょう。
sklearnのデータセットの中にbreast-cancerという乳がんデータセットがあるので、これを使って試します。
まずはデータを読み込んでみましょう。
cancer = datasets.load_breast_cancer() df = pd.DataFrame(cancer.data, columns= cancer.feature_names) df["label"] = cancer.target df.head()

このスクリーンショットは変数が多すぎて読めないかもしれません。
ご自分のpcでコードを実装して試してみてください!
また、labelの中身を確認します。
set(cancer.target)
# 出力結果
{0,1}
このデータのラベルが2つしかないことがわかりますね。
データの分割
では読み込んだデータを教師・テストに分割しましょう。
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, test_size=0.2, random_state=1234)
テストデータを2割、残りを教師データとして分割しました。
この関数はデフォルトでデータをシャッフルしてくれるので、これ以上の操作は不要です。
モデルの学習と評価
以下の流れで学習させます。
- モデルの作成
- LRクラスからLRインスタンスを作る
- モデルの学習
- fitメソッドで学習
clf = LR() # 1 clf.fit(X_train, y_train) # 2
[出力結果]
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
これで学習ができました。
このclfインスタンスのpredictメソッドにテストデータを渡すと、そのテストデータに対する予測ラベルが出てきます。
clf.predict(X_test)
# 出力結果
array([1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 0,
0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1,
1, 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0,
0, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0,
1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1,
0, 1, 0, 0])
また、学習の結果の評価を確認するにはscoreメソッドを使います。
clf.score(X_train, y_train) # 教師データを使った正解率 0.9560439560439561
教師データが高い性能になるのはある程度必然なので、テストデータの方を見てみましょう。
clf.score(X_test, y_test) # テストデータを使った正解率 0.9473684210526315
悪くない値ですね。
これでロジスティック回帰の試し方の解説は終わりです!
もっと深く学ぶには
ロジスティック回帰やその他のデータ解析手法について学びたいならば、書籍やオンライスクールがおすすめです。
とりあえず使ってみたい!というだけならWeb上の記事でも十分勉強できますが(ロジスティック回帰は非常に知名度が高いので、様々な入門記事があります)、前提知識が無いと独学は難しいと思います。
この記事でも、Pythonが書けてscikit-learnがインストールできることを暗黙のうちに前提にしていました。
もっと基礎から、例えば「Pythonってどうやってインストールすればいいの?」という方が「ビジネスの現場で役立つデータ解析方法を最短で学びたい」と思ったならば、侍エンジニアのマンツーマンレッスンがおすすめです。
[su_button url=”https://lp.sejuku.net/lp1_blog_01/?cid=ai_btn1_63333″ target=”blank” style=”3d” background=”#ffffff” color=”#ff9a8f” size=”9″ center=”yes” radius=”10″ icon=”icon: external-link” icon_color=”#fff88f” text_shadow=”0px 0px 10px #808080″]侍エンジニアとは?
詳細はこちらから[/su_button]
仕事に役立つようなデータ解析手法の習得を3ヶ月や6ヶ月の期間、インストラクターとマンツーマンで勉強できます。
是非考えてみて下さい!
まとめ
この記事ではロジスティック回帰について紹介しました。
ロジスティック回帰はアルゴリズムのシンプルさ、経営者層まで広く知られているほどの認知度から、ビジネスの現場で大活躍です。
自分で1から実装するのは難しいですが、scikit-learnなら手軽に使うことができるので、是非実際のデータで使ってプレゼンなどに役立ててください!




